搜索到
1061
篇与
的结果
-
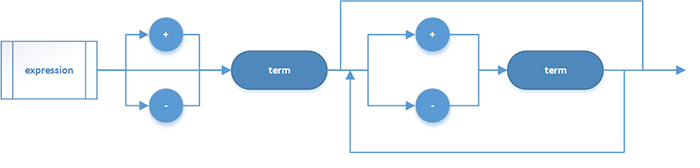
 编译原理与计算器 上次交流会师弟演讲了栈式计算器,这在《数据结构》里也有提到,当时是用C实现了。而这学期学《编译原理》,里面也涉及到数学表达式。两者对比用栈更快,但是使用中间代码可以使到条理更清晰,还可以做很多有趣的扩展。所以这次交流会的内容有着落了。因为想顺便做个简单的 GUI 看看效果,所以打算用 Qt 或 pyQt,但是之前重装了系统,去下载Qt校园网速又渣渣,最后还是用了 Java。语法图先简单的递归定义数学表达式文法,用 EBNF 会比较精炼,但是演讲效果不够图像明显。表达式:项:因子:数字这把所有的数字当做自然数处理:嵌套关系有了语法图就可以从字符串中把一个个有意义的符号(Token)取出来了。现在就要关注在上面的语法图中如何嵌套调用去解析一条数学表达式。比如要解析 25+3/(43-33)-37,如图结合之前的语法图会比较好理解,我在PPT上做了动态图。可以看到,每次都从表达式中递归的判断到终结符,扫描一遍就可以建立中间代码了。中间代码按照数学运算法则建立中间代码,它是一棵树,叶子结点都是数字,越接近根部的点运算优先级越低。举例来说,解析 -25+3/(43-33)-(-37) 生成的中间代码如图所示。可以结合PPT的动态图理解整个建立过程。扫描的时候,树根为数字遇到操作符便往上方长树,树根为操作符遇到更低优先级的操作符也往上长树,其它情况则往下长。代码实现太懒没弄 UML 图,不过类也不多,直接讲吧,完整源码在这里。首先是 Token 类,扫描时就会将字符串生成一个个 Token。private TokenType type; // 该token的类型 private double number; // 数字 private String op; // 操作符我这里是图省事把 Token 也当做中间代码的结点,所以里面还实现树相关的属性和方法,为中间代码的结点单独设计类会更好。private ArrayList children = null; // 孩子 public void addChild(Token token){/*......*/}接下来看 TokenType 类,这里枚举了所有可能的类型。public enum TokenType { //数字 NUMBER, //操作符 PLUS, MINUS, STAR, SLASH, LEFT_PAREN, RIGHT_PAREN, //负数 NEGATE, //结束 EOF; }有了 Token 和 TokenType,Scanner 类负责扫描一遍表达式并提取一个个 Token。因为这里的符号(Token)只有数字与负号(见上面的 TokenType),所以判断起来并不复杂,注意一下处理小数点。// 数字处理 if(Character.isDigit(currentChar) || currentChar == '.') { return extractNumber(); } else { nextChar(); // 先消耗掉这个字符 switch(currentChar) { case '+': return new Token(PLUS, '+'); case '-': return new Token(MINUS, '-'); case '*': return new Token(STAR, '*'); case '/': return new Token(SLASH, '/'); case '(': return new Token(LEFT_PAREN, '('); case ')': return new Token(RIGHT_PAREN, ')'); case (char)0:return new Token(EOF); default : throw new Exception("有未识别的字符 \""+ currentChar + "\" !"); } }Parser 类就完全是对应着上面的语法图去实现了,遇到非终结符便递归,逻辑非常清晰,可以参看源码生成中间代码后,在后端实现一个 Calculator 去计算中间代码,更加简单,自上往下递归计算即可。private double calculate(Token token) throws Exception { if(token != null) { ArrayList children = token.getChildren(); if(children == null) { return token.getNumber(); } else { switch(token.getType()) { case PLUS : return calculate(children.get(0)) + calculate(children.get(1)); case MINUS : return calculate(children.get(0)) - calculate(children.get(1)); case STAR : return calculate(children.get(0)) * calculate(children.get(1)); case SLASH : return calculate(children.get(0)) / calculate(children.get(1)); case NEGATE : return -1 * calculate(children.get(0)); default : throw new Exception("计算出错!" + token.getType().toString()); } } } return 0; }就这样表达式计算就完成了。用 CalcMachine 类测试效果。其中使用正则表达式隐藏异常中不必要的信息。Pattern.compile("^.*Exception:").matcher(e1.toString()).replaceAll("")总结希望大家读完这篇文章后: 学会了理解语法图 学会了简单的词法分析和语法分析 使用递归可以十分灵活、方便 计算器的功能很容易扩展 功能分块可单独测试,便于查错、维护,特别是对于此类逻辑复杂的系统
编译原理与计算器 上次交流会师弟演讲了栈式计算器,这在《数据结构》里也有提到,当时是用C实现了。而这学期学《编译原理》,里面也涉及到数学表达式。两者对比用栈更快,但是使用中间代码可以使到条理更清晰,还可以做很多有趣的扩展。所以这次交流会的内容有着落了。因为想顺便做个简单的 GUI 看看效果,所以打算用 Qt 或 pyQt,但是之前重装了系统,去下载Qt校园网速又渣渣,最后还是用了 Java。语法图先简单的递归定义数学表达式文法,用 EBNF 会比较精炼,但是演讲效果不够图像明显。表达式:项:因子:数字这把所有的数字当做自然数处理:嵌套关系有了语法图就可以从字符串中把一个个有意义的符号(Token)取出来了。现在就要关注在上面的语法图中如何嵌套调用去解析一条数学表达式。比如要解析 25+3/(43-33)-37,如图结合之前的语法图会比较好理解,我在PPT上做了动态图。可以看到,每次都从表达式中递归的判断到终结符,扫描一遍就可以建立中间代码了。中间代码按照数学运算法则建立中间代码,它是一棵树,叶子结点都是数字,越接近根部的点运算优先级越低。举例来说,解析 -25+3/(43-33)-(-37) 生成的中间代码如图所示。可以结合PPT的动态图理解整个建立过程。扫描的时候,树根为数字遇到操作符便往上方长树,树根为操作符遇到更低优先级的操作符也往上长树,其它情况则往下长。代码实现太懒没弄 UML 图,不过类也不多,直接讲吧,完整源码在这里。首先是 Token 类,扫描时就会将字符串生成一个个 Token。private TokenType type; // 该token的类型 private double number; // 数字 private String op; // 操作符我这里是图省事把 Token 也当做中间代码的结点,所以里面还实现树相关的属性和方法,为中间代码的结点单独设计类会更好。private ArrayList children = null; // 孩子 public void addChild(Token token){/*......*/}接下来看 TokenType 类,这里枚举了所有可能的类型。public enum TokenType { //数字 NUMBER, //操作符 PLUS, MINUS, STAR, SLASH, LEFT_PAREN, RIGHT_PAREN, //负数 NEGATE, //结束 EOF; }有了 Token 和 TokenType,Scanner 类负责扫描一遍表达式并提取一个个 Token。因为这里的符号(Token)只有数字与负号(见上面的 TokenType),所以判断起来并不复杂,注意一下处理小数点。// 数字处理 if(Character.isDigit(currentChar) || currentChar == '.') { return extractNumber(); } else { nextChar(); // 先消耗掉这个字符 switch(currentChar) { case '+': return new Token(PLUS, '+'); case '-': return new Token(MINUS, '-'); case '*': return new Token(STAR, '*'); case '/': return new Token(SLASH, '/'); case '(': return new Token(LEFT_PAREN, '('); case ')': return new Token(RIGHT_PAREN, ')'); case (char)0:return new Token(EOF); default : throw new Exception("有未识别的字符 \""+ currentChar + "\" !"); } }Parser 类就完全是对应着上面的语法图去实现了,遇到非终结符便递归,逻辑非常清晰,可以参看源码生成中间代码后,在后端实现一个 Calculator 去计算中间代码,更加简单,自上往下递归计算即可。private double calculate(Token token) throws Exception { if(token != null) { ArrayList children = token.getChildren(); if(children == null) { return token.getNumber(); } else { switch(token.getType()) { case PLUS : return calculate(children.get(0)) + calculate(children.get(1)); case MINUS : return calculate(children.get(0)) - calculate(children.get(1)); case STAR : return calculate(children.get(0)) * calculate(children.get(1)); case SLASH : return calculate(children.get(0)) / calculate(children.get(1)); case NEGATE : return -1 * calculate(children.get(0)); default : throw new Exception("计算出错!" + token.getType().toString()); } } } return 0; }就这样表达式计算就完成了。用 CalcMachine 类测试效果。其中使用正则表达式隐藏异常中不必要的信息。Pattern.compile("^.*Exception:").matcher(e1.toString()).replaceAll("")总结希望大家读完这篇文章后: 学会了理解语法图 学会了简单的词法分析和语法分析 使用递归可以十分灵活、方便 计算器的功能很容易扩展 功能分块可单独测试,便于查错、维护,特别是对于此类逻辑复杂的系统 -
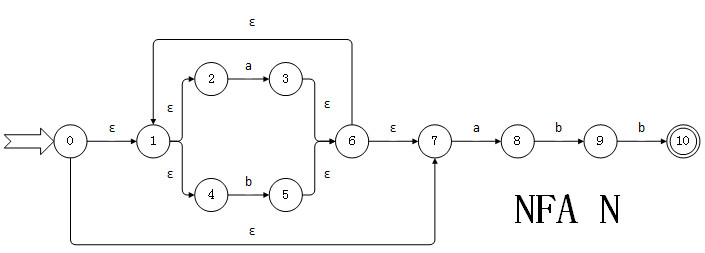
NFA与DFA的转换与优化 上一节《编译原理》课讲到了NFA(不确定的有穷自动机)向DFA(确定的有穷自动机)转换。考试要考,所以要手写变换过程,很繁琐,也很有趣。所以周末用python给实现了,并利用动态规划进行优化。转换方法这里主要涉及到对状态集合I的两个操作: 求ε-闭包。表示为ε-closure(I),是指I中的任何状态S经过任意条ε弧能到达的状态的集合。 求I的α弧转换。表示为move(I,α),是指I中某一状态经过一条α弧到达的状态的集合。 比如说这里有一个NFA N:因为NFA是一个五元组,N=(K,E,f,S,Z),即为(状态集合,弧集合,转换集合,开始状态集合,终结状态集合),所以由图可知:NFA N = ({0,1,2,3,4,5,6,7,8,9,10},{a,b},f,{0},{10}),其中 f(0,ε) = {1} f(1,ε) = {2,4} f(2,a) = {3} f(3,ε) = {6} f(4,b) = {5} f(5,ε) = {6} f(6,ε) = {1,7} f{7,a} = {8} f(8,b) = {9} f(9,b) = {10} 那么ε-closure(0)={0,1,2,4,7}move({0,1,2,4,7},a) = {3,8}ε-closure({3,8})={1,2,3,4,6,7,8}可以借助表格来观察整个求解过程,每次求解后如果产生新集合,就会记录下来继续算,直到没有新集合为止。 T A=ε-closure(move(T,a)) B=ε-closure(move(T,b)) ε-closure(s)={0,1,2,4,7}=T0 {1,2,3,4,6,7,8}=T1 {1,2,4,5,6,7}=T2 T1 T1 {1,2,4,5,6,7,9}=T3 T2 T1 T2 T3 T1 {1,2,4,5,6,7,10}=T4 T4 T1 T2 此时T列下的集合{T0,T1,T2,T3,T4}就是DFA的状态,其中含有NFA初始状态的集合为DFA的初始状态({T0}),含有NFA终结状态的集合为DFA的终结状态({T4})。所以由NFA转换后的DFA为:实现首先是数据存储格式,使用json存储NFA的五元组:{ "k" : ["0","1","2","3","4","5","6","7","8","9","10"], "e" : ["a","b"], "f" : { "0" : { "#" : ["1", "7"] }, "1" : { "#" : ["2", "4"] }, "2" : { "a" : ["3"] }, "3" : { "#" : ["6"] }, "4" : { "b" : ["5"] }, "5" : { "#" : ["6"] }, "6" : { "#" : ["1", "7"] }, "7" : { "a" : ["8"] }, "8" : { "b" : ["9"] }, "9" : { "b" : ["10"] } }, "s" : ["0"], "z" : ["10"] }读入时做了一些简单的判断,其实还可以做得更加周全,比如初始集s和终结集z是否被状态集k包含,等等。read()了之后就会把五元组包装返回。def read(input): try: nfa = json.load(open(input,"r")) for i in nfa["f"]: if not i in nfa["k"]: raise Exception("Set f contains iterms that not belongs to set k.") for j in nfa["f"][i]: if not j in nfa["e"] and not j == '#': raise Exception("Set f contains iterms that not belongs to set e.") return (set(nfa["k"]), set(nfa["e"]), nfa["f"], set(nfa["s"]), set(nfa["z"])) except IOError: print "File no found!" sys.exit(1) except (KeyError, TypeError): print "Input data error!" sys.exit(1) except Exception, e: print(e.args[0]) sys.exit(1)使用creat_memo()接下来为计算创建缓存,因为计算闭包有大量的重复计算。memo是一个字典,以e集合(弧集合)的元素为键,每一个键对应的值也是一个字典,在计算闭包的过程中缓存该状态的闭包。(见closure())def creat_memo(e_set): memo = {} for i in e_set: memo[i] = {} memo['#'] = {} return memo从文章开始时提到的转换方法很容易可以看到,两个操作有很大的相似性,所以我把它们封装成一个函数closure()了,调用时使用各自的接口。对应上面提到的弧转换操作,move()中的参数s和arc表示求move(s,arc),而ph_closure()的arc默认为ε,这里用"#"表示。def move(f, memo, s, arc): return closure(f, memo[arc], s, arc) def ep_closure(f, memo, s): return closure(f, memo["#"], s, '#')closure()是本程序的核心部分,当它接受了一个集合c_set时,会对c_set中的元素一一进行求闭包或者弧转换,再合并集合。在进行计算之前先查看缓存memo,看看之前有没有计算过,有就直接合并,没有就先计算出结果,在memo记录之后再进行合并。对于求闭包,因为是ε,所以每次要先包含本身,而弧转换则不需要。注意memo[s] = set([s]),必须是set([s])不能是set(s),因为s为字符串,set(s)会把s中的每个字符都拆开。接下来判断f转换中是否存在有关f(s,arc)的定义,存在的话: 闭包情况:深度优先递归的计算集合f(s,arc)的闭包,将它们合并回来。比如上面的NFA例子,一开始求ε-closure(0)的时候,发现f(0,ε)={1,7},所以继续计算ε-closure(1)和ε-closure(7)。.....一直计算到尽头。每次递归计算过程中也会在memo上记录,所以整个计算过程会越来越快。 弧转换情况:由于弧只需要判断状态s的下个一个arc弧连接的状态,所以不需要递归,直接得出结果。 def closure(f, memo, c_set, arc): res = set() for s in c_set: if not s in memo: memo[s] = set() if arc == '#': #Attention here. Has to be a list memo[s] = set([s]) if s in f: if arc in f[s]: if arc == '#': memo[s] |= closure(f, memo, set(f[s][arc]), arc) else: memo[s] = set(f[s][arc]) res |= memo[s] return rescreat_dfa返回一个空的dfa结构,calc_dfa代表了上面提到的表格的运算过程,并把表格的内容保存到dfa结构中。先对初始状态集k求闭包,接下来为每个弧求弧转换闭包ε-closure(move(s, arc))。出现新集合就交给queue队列,并在dfa["k"]中做记录。我这里是利用集合在dfa["k"]中的index作为dfa状态的命名。def creat_dfa(e_set): dfa = {} dfa["k"] = [] dfa["e"] = list(e_set) dfa["f"] = {} dfa["s"] = [] dfa["z"] = [] return dfa def calc_dfa(k_set, e_set, f, s_set, z_set): dfa = creat_dfa(e_set) dfa_set = [] memo = creat_memo(e_set) ep = ep_closure(f, memo, s_set) #Attention here. Has to be a list queue = deque([ep]) dfa_set.append([ep]) dfa["k"].append("0") dfa["s"].append("0") if not len(ep&z_set) == 0: dfa["z"].append("0") i = 0 while queue: T = queue.popleft() j = "" index = str(i) i = i + 1 dfa["f"][index] = {} for s in e_set: t = ep_closure(f, memo, move(f, memo, T, s)) try: j = str(dfa_set.index(t)) except ValueError: queue.append(t) j = str(len(dfa_set)) dfa_set.append(t) dfa["k"].append(j) dfa["f"][index][s] = j if not len(t&s_set) == 0: dfa["s"].append(j) if not len(t&z_set) == 0: dfa["z"].append(j) return dfa生成json的write_dfa和程序的其余代码:def write_dfa(dfa, f): f = open(f, "w") f.write(json.dumps(dfa)) f.close() def main(): (k_set, e_set, f, s_set, z_set) = read("NFA.json") dfa = calc_dfa(k_set, e_set, f, s_set, z_set) write_dfa(dfa, "DFA.json") if __name__ == '__main__'附上最后生成的json代码,就是上面的图DFA M{ "k": ["0", "1", "2", "3", "4"], "z": ["4"], "e": ["a", "b"], "s": ["0"], "f": { "1": { "a": "1", "b": "3" }, "0": { "a": "1", "b": "2" }, "3": { "a": "1", "b": "4" }, "2": { "a": "1", "b": "2" }, "4": { "a": "1", "b": "2" } } }
-
Jekyll-bootstrap Not Updating Problem Fixed I had a jekyll blog on the github and changed it to Jekyll-bootstrap yesterday.I tested it locally, everything was ok. Pushed successfully. But my github pages didn't change.After debugging, I realised that the problem occured right after the theme hooligan was installed.To fix this problem, you only need to: Remove the _theme_packages file: git rm _theme_packages Create a .gitignore file in the root of your Page repository. Put _theme_packages/* into the file. Better install the theme again. This solution worked for me.我昨天把jekyll换成了jekyll-bootstrap,在本地测试成功,push也成功了。但是github pages一直没有改变。重复安装了很多次,终于发现当我安装完hooligan主题后,github pages就没反映了。最后发现是主题下载包_theme_packages跟github有冲突。所以,先remove掉git rm _theme_packages在根目录添加.gitignore文件,写入_theme_packages/*最好把主题重新安装一次如果上面的办法没用的话,我建议删掉仓库重新来一遍,我就是这样成功的,注意发布之后有可能要等一会才有效哦。
-
-
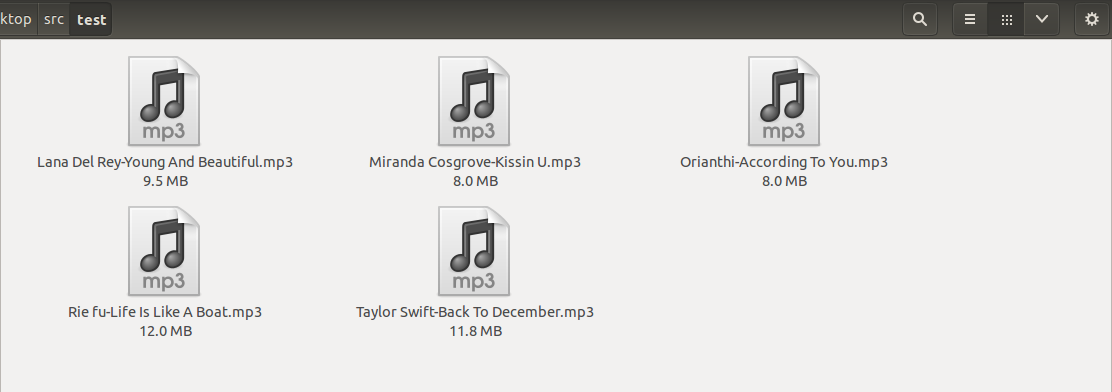
为mp3更新高清封面 我是个受不了安静的人,干活的时候没有音乐不行。我也是欧美音乐fans,多年来积累了不少或热门或冷门的音乐。无奈这些音乐大多没有封面,或者供应商为了节约流量用了压缩的小图,于是在移动设备上显示得惨不忍睹。忍了一段时间后终于忍不住了,亲自改一下。遍历mp3开始的时候当然是要先找到mp3文件了。使用os.walk递归的查找mp3,把文件名和路径存下来:import os def mp3_find(source_path): mp3_list = [] for root, dirs, files in os.walk(source_path): map(lambda x: mp3_list.append((root, x[:-4])), filter(lambda x: x[-4:] == '.mp3', files)) return mp3_list测试一下,放一些mp3文件在test文件夹:if __name__ == '__main__': mp3_list = mp3_find(r'test') print mp3_list读取id3信息接下来要读取mp3的id3信息,我用了eyed3,它不支持python3所以我用的是python2.7import eyed3,sys def mp3_load(mp3_path, mp3_name): try: id3 = eyed3.load(os.path.join(mp3_path, mp3_name+'.mp3')) return id3 except IOError: print ' '.join([mp3_name,'read error.']) sys.exit(1)测试一下mp3_process:def mp3_process(mp3_list): for path, name in mp3_list: id3 = mp3_load(path, name) print ' '.join(map(str, [id3.tag.title,id3.tag.artist,id3.tag.album])) if __name__ == '__main__': mp3_process(mp3_find(r'test'))搜索得到名字之后就要从网络抓取图片,这里使用了豆瓣音乐Api v2,参看音乐的返回格式,默认返回到是小图spic来的,手动改成大图lpic。这里使用了比较肮脏的手段去除ident的标点符号。import json,re def search(ident): ident = ident.translate(string.maketrans(string.punctuation, ' ')) url = r'http://api.douban.com/v2/music/search?q=' + ident mp3_json = json.load(urllib2.urlopen(url), encoding="utf-8") try: if mp3_json['count'] > 0: return re.sub(r'/spic/', r'/lpic/', mp3_json['musics'][0]['image']) except (KeyError, ValueError): pass return False有的mp3可能没有id3标签,所以如果search返回False的话还要按文件名搜一遍。修改mp3_process测试一下def mp3_process(mp3_list): for path, name in mp3_list: id3 = mp3_load(path, name) img = search(' '.join(map(str, [id3.tag.title,id3.tag.artist,id3.tag.album]))) if not img: img = search(name) if not img: continue写入封面因为我的音乐都是英语的,所以编码用latin1保持最大的可用性,utf-8和utf-16有的移动设备会显示不出封面,注意中文不能使用latin1。def mp3_burn(id3, img): id3.tag.images.set( type=3, img_url=None, img_data=urllib2.urlopen(img).read(), mime_type='image/jpeg', description=u"Front cover") id3.tag.save(version = (2, 3, 0), encoding = 'latin1')再次修改mp3_process测试一下,这次是最终版了def mp3_process(mp3_list): faild_list = [] for path, name in mp3_list: print '-- %s:' %name id3 = mp3_load(path, name) img = search(' '.join(map(str,filter(lambda x: x, [id3.tag.title,id3.tag.artist,id3.tag.album])))) if not img: img = search(name) if img: mp3_burn(id3, img) else: faild_list.append(name) return faild_list效果随机找来一坨mp3,如图,可以看到是没有封面的。跑一遍程序,再查看,(ubuntu下不知道怎么刷新缩略图缓存,我是把文件夹复制一份)后话豆瓣的api是有频率限制的,最好申请一个APIKey,或者使用代理,也可以在循环中加入sleep凑合用,一般情况都会没问题。完整源码在这里。