搜索到
1061
篇与
的结果
-
 脆弱的力量 今天看到了个TED Talk “Brené Brown: The power of vulnerability”,讲者讲诉了自身的经历后得出结论要接受脆弱: Let ourselves be seen, deeply seen, vulnerably seen. Love with our whole hearts, even though there is no guarantee. Practice gratitude learn into joy. Believe that we are enough. 讲者还有一个重要的论点——我们在“麻痹脆弱”(numb vulnerability)。教父说过“Never hate your enemies. It affects your judgment.”我认为是讨厌做一件事才会麻痹(拖延),喜欢做的事从来不会拖延。像上不喜欢课经常会走神,而编程有时候爽起来会编通宵。而我的一个师兄有句口头禅“讨厌做一件事是因为做不好,做好了就会喜欢了”。是不是有点悖论的味道。但是很多时候就像冬天洗冷水澡一样,“忍一下就不痛了”。正所谓凡事开头难,但只有拿起球杆打几盘才知道合不合手。讲者还有个很有趣的定义Blame - A way to discharge pain and discomfort.以后想要责怪别人的时候想想这句话,把口收住。学学Vito Corleone的胸襟。最后奉上一张图,时刻警惕,不要成为工厂刻出来的模子瞎扯完了,洗洗睡。
脆弱的力量 今天看到了个TED Talk “Brené Brown: The power of vulnerability”,讲者讲诉了自身的经历后得出结论要接受脆弱: Let ourselves be seen, deeply seen, vulnerably seen. Love with our whole hearts, even though there is no guarantee. Practice gratitude learn into joy. Believe that we are enough. 讲者还有一个重要的论点——我们在“麻痹脆弱”(numb vulnerability)。教父说过“Never hate your enemies. It affects your judgment.”我认为是讨厌做一件事才会麻痹(拖延),喜欢做的事从来不会拖延。像上不喜欢课经常会走神,而编程有时候爽起来会编通宵。而我的一个师兄有句口头禅“讨厌做一件事是因为做不好,做好了就会喜欢了”。是不是有点悖论的味道。但是很多时候就像冬天洗冷水澡一样,“忍一下就不痛了”。正所谓凡事开头难,但只有拿起球杆打几盘才知道合不合手。讲者还有个很有趣的定义Blame - A way to discharge pain and discomfort.以后想要责怪别人的时候想想这句话,把口收住。学学Vito Corleone的胸襟。最后奉上一张图,时刻警惕,不要成为工厂刻出来的模子瞎扯完了,洗洗睡。 -
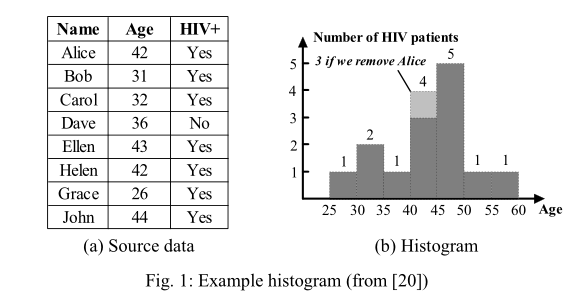
Damson演示:用于大数据分析的差分隐私 原文:Demonstration of Damson: Differential Privacy for Analysis of Large Data摘要—— Damson为生物医学研究的结果提供较强的隐私保护,是一种强大的新型工具。Damson基于差分隐私算法,即使攻击者掌握了大量的背景知识,也无法从公开的结果中推断出某个个体是否存在。Damson支持生物医学研究中常见的各种分析任务,包括直方图,边缘,数据立方体,分类,回归,聚类,点对点选择计数。此外,Damson包含一个高效的查询优化引擎,从而在获得高精度的分析结果同时最小化隐私成本。简介隐私问题已经成为研究者获取生物医学数据的主要障碍。简单的去身份识别方法,如去掉个体的名字和ID,很难保证足够的隐私保护。主要的原因是,攻击者虽然不能直接从公开的数据中恢复个体的身份信息,但他往往可以结合额外的背景知识去重新识别个体的身份。数据安全研究人员已经想出了一些具有鲁棒性和通用性的重识别算法。比如,[13]的作者仅仅通过从IMDB网站(www.imdb.com)公开的数据集中获取背景知识,就可以在Netflix电影评级网站(www.netflixprize.com)的匿名数据中成功重识别个体。而且,对于一些生物医学的数据集,哪怕仅仅是从数据中导出来的统计结果,也可能会泄露隐私信息。一个著名的例子是全基因组关联研究(GWASs)——生物信息学的一个热门话题,研究一群患同种疾病的病人(比如糖尿病)中的DNA样本,希望能发现疾病与人类DNA中的某些特定的部分(叫做SNPs)之间的联系。一种最近研发的攻击[7],通过目标个体的DNA样本和从HapMap公开的仓库(www.hapmap.org)中获取的参考人口(比如欧洲、亚洲等等),就可以重识别出该个体。一种改进的攻击[16]更是威胁到未来发布的所有GAWS成果,这些数据在现在的生物医学研究期刊上很容易就可以找到。回应上述问题,近期掀起一股热潮研究隐私数据的发布和分析。早期的方案使用简单的方法实现数据匿名化,比如k-匿名(k-anonymity)将每个个体隐藏在一个新的群中,这个群包含k个难以区分的新个体[17]。这些方法难以对抗拥有背景知识的攻击者,比如,当攻击者知道了群中的k-1个个体,k-匿名便失去了作用。而且,因为没有形式上的隐私保证,即使攻击者没有掌握任何背景知识,满足k-匿名的算法是否真的可以保护个体的隐私,这里依然存在疑问。举例来说,l-多样性(l-diversity)[11]解决了这个问题,攻击者可以从缺少多样性(比如群中k个个体都患同种疾病)的k-匿名群中推断出敏感信息,且l-多样性本身也在不停的被挑战和补充[9]。这些问题激发出一些更有效的解决方法,这些方法基于更强大的方案,有稳定,可验证的隐私保证。差分隐私[5]就是这么一种方法,它保证攻击者无法推测出个体的存在与否,即使他已经获得了数据集中其余所有个体的准确信息。推测的难度由参数ε决定,ε也叫做隐私预算(privacy budget)。实现差分隐私的一种流行方法论是将随机噪声注入到公开的统计查询结果中[6]。这里的查询是指任意有唯一输出的函数,涵盖了最常见的一些生物医学分析任务。根据组合律,应答隐私预算为ε1,.....,εn的多重查询q1,......,qn,分别满足(ε1+......+εn)-差分隐私。设计差分隐私方案的主要难题是最大化查询准确率。虽然存在一种通用方案理论上可以应答所有查询,但在实际应用时准确率往往表现的很糟糕。因此,过去为了解决多种类型的查询往往需要提供更多的方案。在ADSC我们建立了Damson系统[3],整合了大量的差分隐私算法去执行常见的生物医学研究任务。Damson的贡献是巨大的。第一,Damson包含了一些新的算法;第二,差分隐私的不同解决方案往往对数据和查询有不同的前提和要求,因此将它们都整合到一个系统中非常不容易;第三,高效率、高准确率、低隐私预算需求地应答多重查询极具挑战性,必须具备高效的查询优化引擎;最后,Damson有相当高的使用价值,因为它能够为基于敏感数据的生物医学分析提供强隐私保障,而此前的方法都很难做到。本次演示聚焦于Damson的两个主要方面,1)Damson在多种常见的生物医学分析任务中表现如何;2)Damson在这些任务中是如何利用最少的隐私代价实现较高的准确率。接下来的II、III节会分别详述Damson在这两方面的设计。差分隐私下的生物医学分析在这里我们演示Damson中已实现的7种不同类型的分析任务:直方图(histogram)、数据立方体(data cube),边缘(marginal)、分类(classification)、聚类(clustering)、回归(regression)和点对点选择计数(ad-hoc selection-count)。 直方图(Histogram)直方图通过一组不相交的块来概括数据的分布,每个块代表在对应属性取值范围上的记录的数目。图1a是一个样例数据集,图1b是建立在Age属性上的直方图(提取自参考文献[20])。直方图中的每个块(以图1b中年龄40-50为例)包含了源数据(图1a)中对应记录的数目(4个)。图1b是一种等宽直方图,每个块代表相同的属性取值间距。同时,通常来说最精确的直方图有着最好的粒度,比如让每个块只代表一个年龄。但是,从我们的演示中[20]看到,由于向公布的直方图中注入了额外的噪声,差分隐私下最好的直方图通常既不是等宽的,也没有最好的粒度。特别指出,合并连续的块会带来信息损失,但同时也会减少等量的差分隐私所需的额外噪声。直方图发布的一个主要技术难题是,除了其公布的统计数值外,直方图的结构也可能泄露敏感数据。举例说,在图1中,如果我们去掉Alice的记录,优化直方图的结构有可能不同。Damson使用[20]提出的动态规划算法会自动建立最好的差分隐私直方图。此算法会根据差分隐私的需要在块计数和直方图结构中都注入随机噪声。 数据立方体(Data Cube)数据立方体是在多维数据上执行OLAP操作的重要工具。图2显示了一个示例计数数据立方体,取自[4]。源数据(称作事实表fact table)包含3个属性,性别(Sex)、年龄(Age)、工资(Salary)。数据立方体包含多个汇总表,称作方体(cuboid)。举例说,图2b显示了工资属性上的方体,每行记录包含了事实表上特定工资值(如10-50k)元组的计数(3个)。一个方体也可以涵盖多个属性,如图2d中包含了年龄和工资两个属性,其中每行记录包含了事实表上特定的年龄-工资组合(如年龄:21-30,工资:10-50k)的元组的计数(3个)。注意到工资方体可以通过年龄-工资方体计算得出,只需将后者中所有相同工资的记录合并。一般来说,一个涵盖集合A的“较粗”的方体总是可以通过一个包含A子集的“较细”的方体推导出来。事实表本身可以看做是“最细”的方体,可以导出其它任意的方体。数据立方体的发布有两个难题。第一是确定应该发布哪些方体。发布一个方体需要占用一部分的隐私预算,会使到其它的方体噪声增多(即准确率下降)。另一方面,如果我们不直接发布方体C,而是通过更细的方体C'去导出C,那么由于噪声的累积,C的准确率将会很糟糕。举例说,假如我们忽略工资方体本身,而用年龄-工资方体表计算出工资方体,后者计数的准确率将会比前者的低很多。(译者注:原文这里的前者和后者是反过来的)因为年龄方体中的每个计数都是从年龄-工资方体中多个记录中统计出来的,噪声也会随之积累。第二个难题是保持关联方体间的一致性。例如,假设同时发布年龄方体和年龄-工资方体,因为两者添加的噪声是不相关的,年龄方体中的一条记录与年龄-工资方体中对应记录统计出来的结果会不相同,这导致了不一致性问题。Damson优雅的解决了这两个问题,其数据立方体模块会自动选择一组方体发布,最大限度地提高整体精度,并对不同方体强制执行一致性。 边缘与朴素贝叶斯分类(Marginal and Naive Bayes Classification)边缘相当于数据立方体中的方体,它是一张表,对给出的属性集,统计事实表上每种可能的属性组合的记录数。数据立方体与边缘的主要区别是,数据立方体是公布了所有的方体,而边缘发布则通常会先给出一组属性组合,然后只公布相对应的边缘。比如,在图2中,我们可能会只想分别发布年龄-性别边缘和年龄-工资边缘。差分隐私下发布数据立方体的难题同样存在边缘发布中,也就是,发布最优的边缘和强制他们的一致性。然而,这些问题在边缘发布中相对没那么重要,因为边缘发布通常只会发布少量的边缘,而不像数据立方体一样发布全部的方体。同时,发布的边缘集合通常是基于一个更复杂的分析任务。朴素贝叶斯分类就是这样一种任务,其目的是使用其余的属性(称为特征属性)预测一个属性的值(称为目标属性)。具体而言,朴素贝叶斯分类可分为两个阶段,训练阶段和测试阶段。在训练的过程中,朴素贝叶斯计算出一个概率模型,记录目标属性和每个特征属性之间的相关性。虽然不同的特征属性也会表现出相关性,但朴素贝叶斯为了简化,忽略了此类相关性(因此称为朴素贝叶斯)。训练阶段生成的模型会用在接下来的测试阶段中,用于计算目标属性每个取值之间的可能性,然后取最大可能的取值。要使用朴素贝叶斯分析,我们需要发布m+1个边缘,m是特征属性的个数。这里包括了一个目标属性的边缘,其余m个分别是目标属性与其中一个特征属性组合的边缘。比如,假设工资是目标属性,性别和年龄是特征属性。朴素贝叶斯需要发布3个边缘,分别是工资边缘、性别-工资边缘和年龄-工资边缘。在边缘发布中,一个共同的目标是最小化整体相对误差,而不是整体绝对误差[17]。这需要为较小的计数添加较小的噪声,较大的计数添加较大的噪声。这在差分隐私下实质上就是隐私预算的分配问题,因为注入较小的噪声需要占用隐私预算更大的一部分。主要的难题是预算分配过程本身也要以差分隐私的方式运行。Damson通过[17]提出的迭代方式解决此问题,高效率的找出最佳的预算分配,最小化发布边缘的整体相对误差,并且满足差分隐私要求。 回归(Regression)回归分析在医学研究中尤其有用。例如,通过一些风险因子比如年龄、体重、病史等等去预测一个病人的诊断结果。Damson目前支持两种常见的回归分析:线性回归(linear regression)和逻辑回归(logistic regression)。前者试图在不同属性之间确定线性相关,而后者则类似于线性分类器。如图3a是一个线性回归的例子,其中包含两个属性:性别和医疗费用,围绕在直线附近的点是病例。线性回归的目标是找到一条线,到所有点的总距离最小。图3b是逻辑回归的一个例子,目的是区分出糖尿病人。这里有两个特征属性,年龄和胆固醇含量。逻辑回归在特征空间里(如年龄-胆固醇含量平面)确定的一条线,满足(1)线的一边有最多的糖尿病人,另一边有最多的非糖尿病人;(2)对于“糖尿病”的一边,离线越远的病人越可能患糖尿病,对于“非糖尿病”的一边,离线越远的病人越不可能患糖尿病。在差分隐私下进行回归比单纯的计数要复杂的多,因为很难确定满足私隐保证的噪声数量[1][23]。特别是,线性回归和逻辑回归都涉及到最优化程序(optimization program)。逻辑回归最优化程序的最优解并没有一个闭式数学表达式(closed-form mathematical expression),只能用数值表示,因此很难做敏感度分析。而尽管线性回归存在一个闭式最优解,但在此解上直接进行敏感度分析会导致敏感度过高,从而引起过高的噪声水平。Damson通过函数机制(Function Mechanism)解决上述问题,向最优化程序上的目标函数注入随机噪声,而不是注入到函数的解上。如[23]所示,利用合适数量的训练样本,函数机制就可以使得Damson在低隐私预算消耗下实现高精度的回归分析。 聚类(Clustering)给出一组数据点,聚类的目标是从中找出没有预定义的数据簇,满足此条件的相似的点属于同一个簇,不相似的点会被分到不同的簇中。Damson使用了一个简单但强大的聚类技术:K-means聚类。k-means被广泛用于大量的分析任务。k-means接收一个参数k,然后找出k个中心点,使到每个数据点到它最近的中心点的总距离最小。每个中心点形成一个簇,每个数据点属于离该点最近的中心点的簇。图4是聚类分析的一个例子,数据依据三个中心点进行聚类。注意中心点可以是任意的点,而不必是其中一个数据点。图中的三条直线表示不同聚类间的边界。寻找k-means的最优解是一个著名的NP难题。而且,最优的k-means有较高的敏感度,需要大量的干扰,这样会使得结果几乎完全随机。对于差分隐私下的k-means聚类,Damson当前的做法是使用PINQ[12]中提出的迭代算法。虽然此算法没有提供任何的质量保证,但在实际应用中的表现通常都很好。当前正在改进Damson的k-means聚类模型,将使用有质量保证的新算法。 点对点选择计数(Ad-Hoc Selection-Count)上述的每个分析都是为了解决某个具体的分析任务,这些任务在过去中都有明确定义并且经常用到,都是对整个数据集进行操作。在实际应用中,研究人员有时需要针对数据的某个子集进行点对点分析。Damson要处理一大类这样的分析,即范围计数查询,对落入用户指定的属性范围中的记录进行计数。举一个实际的例子,一间药物公司在展开临床试验之前,有时需要先知道一个地区(如新加坡)中是否存在充足的满足要求的病人。比如要求年龄在40-50岁之间,收缩压在120-140之间。不像直方图或者边缘一样有预先定义好的范围,这里的查询可以有任意的范围,可以选择任意的属性组合。Damson内部的解决方案是基于DP树结构[14](DP-tree Structure),有效地处理任意维度的范围计数查询。DP树超越了我们之前的方案Privlet[19][18],对于等量的私隐预算DP树有更高的准确度,尤其在更高维度的查询上。我们正在扩展Damson,使之不仅支持计数和范围,还支持集合(aggregates)和选择标准(selection criteria)。 Damson中的查询优化传统来说,查询优化主要是为了节约运算时间。然而在一个符合差分隐私的系统中,查询优化还需要优化分析结果的准确率和隐私预算的消耗。Damson结合两大技术,分别针对批量查询和相对误差最小化。 批量查询过程(Batch Qurey Processing)初次在[8]显示,相对于单独地应答,使用优秀策略应答批量线性查询的总体准确率要更高。所谓的策略这里是指处理不同组的查询,合并它们的结果去应答原始的查询。然而,[8]中提到的方案更倾于理论化,实际中甚至不能处理中等大小的数据集。Damson使用[22]提到的新方法解决此问题,该方法高效、可扩展,有效的找出最佳的策略。此方法的主要思想是找出可以近似地应答输入的策略,而不严格要求准确。这些近似的误差是可以控制的,而且相比注入到查询结果中的噪声,此类误差通常也是可以忽略的。这里将会演示由Damson计算出的策略查询,看看这些查询如何合并,以较少误差去应答原始的查询。 相对误差最小化(Raletive Error Minimization)当前大部分满足差分隐私的解决方案都是去最小化查询结果的绝对误差。然而,对于大部分的应用,包括在II-C节讨论的边缘发布,最小化总体相对误差更有意义。直观上看,结果较小的查询对噪声更敏感。Damson结合iReduct技术[17]去实现相对误差最小化。除了差分隐私边缘计算的应用,damson还可以最小化批量点对点查询的总体相对误差,只需小心地为每个查询分配隐私预算。我们将展示Damson如何计算最佳的预算分配,使到输入查询的总体相对误差最小化。 结论Damson在不侵犯个体隐私的前提下,帮助研究人员在敏感数据上进行常见的分析。我们将展示Damson如何支持各种各样的分析任务,从简单的任务如计数、直方图和边缘,到复杂的任务如分类和聚类。同时,我们将演示Damson如何利用低隐私损耗、低系统负担,高准确率的完成上述的这些任务。考虑到系统的优势,我们预计Damson将会被广泛的应用,特别是生物医学领域。参考文献 K. Chaudhuri and C. Monteleoni. Privacy-Preserving Logistic Regression. NIPS, 2008. K. Chaudhuri, C. Monteleoni, and A. D. Sarwate. Differentially Private Empirical Risk Minimization. Journal of Machine Learning Research, 12:1069-1109, 2011. Damson. http://differentialprivacy.weebly.com/ B. Ding, M. Winslett, J. Han, and Z. Li, Differentially Private Data Cubes: Optimizing Noise Sources and Consistency. ACM SIGMOD, 2011. C. Dwork. Differential Privacy. ICALP, 2006. C. Dwork, F. McSherry, K. Nissim, and A. Smith. Calibrating noise to sensitivity in private data analysis. TCC, 2006. N. Homer, S. Szelinger, M. Redman, D. Duggan, W. Tembe, J. Muehling, J. V. Pearson, D. A. Stephan, S. F. Nelson, and D. W. Craig. Resolving Individuals Contributing Trace Amounts of DNA to Highly Complex Mixtures Using High-Density SNP Genotyping Microarrays. PLoS Genetics, 4(8), 2008. C. Li, M. Hay, V. Rastogi, G. Miklau, A. McGregor. Optimizing Linear Counting Queries under Differential privacy. PODS, 2010. N. Li, T. Li, S. Venkatasubramanian. t-Closeness: Privacy Beyond k-Anonymity and l-Diversity. IEEE ICDE, 2007. Y. Li, Z. Zhang, M. Winslett, Y. Yang. Compressive Mechanism: Utilizing Sparse Representation in Differential Privacy. WPES, 2011. A. Machanavajjhala, J. Gehrke, D. Kifer. l-Diversity: Privacy Beyond k-Anonymity. IEEE ICDE, 2006. F. McSherry. Privacy Integrated Queries. ACM SIGMOD, 2009. A. Narayanan, V. Shmatikov. Robust De-anonymization of Large Sparse Datasets. IEEE Symposium on Security and Privacy, 2008. S. Peng, Y. Yang, Z. Zhang, M. Winslett and Y. Yu. DP-Tree: Indexing Multi-Dimensional Data under Differential Privacy. ACM IGMOD, 2012, poster. L. Sweeney. k-Anonymity: A Model for Protecting Privacy. International Journal on Uncertainty, Fuzziness and Knowledge-Based Systems. 10(5): 557-570, 2002. R. Wang, Y. Li, X. Wang, H. Tang, and X. Zhou. Learning Your Identity and Disease from Research Papers: Information Leaks In Genome Wide Association Study. ACM CCS, 2009. X. Xiao, G. Bender, M. Hay, and J. Gehrke. iReduct: Differential Privacy with Reduced Relative Errors. ACM SIGMOD, 2011. X. Xiao, G. Wang, and J. Gehrke. Differential privacy via wavelet transforms. IEEE ICDE, 2010. X. Xiao, G. Wang, and J. Gehrke. Differential privacy via wavelet transforms. IEEE TKDE, 23(8):1200-1214, 2011. J. Xu, Z. Zhang, X. Xiao, Y. Yang, and G. Yu. Differentially Private Histogram Publication. IEEE ICDE, 2012. Y. Yang, Z. Zhang, G. Miklau, M. Winslett and X. Xiao. Differential Privacy in Data Publication and Analysis. ACM SIGMOD, 2012, tutorial. G. Yuan, Z. Zhang, M. Winslett, X. Xiao, Y. Yang and Z. Hao. Low-Rank Mechanism: Optimizing Batch Queries under Differential Privacy. PVLDB, vol. 5, 2012. J. Zhang, Z. Zhang, X. Xiao, Y. Yang and M. Winslett. Functional Mechanism: Regression Analysis under Differential Privacy. PVLDB, vol. 5, 2012.
-
解决 Ubuntu 笔记本发热问题 笔记本发热绝大多数情况是因为CPU和双显卡。先排除双显卡问题ubuntu自带双显卡控制,该功能还在debug状态,但是在13.10上已经比较稳定了。13.10之前的需要先加载进来mount -t debugfs debugfs /sys/kernel/debug查看显卡情况sudo cat /sys/kernel/debug/vgaswitcheroo/switch可以看到0:IGD:+:Pwr:0000:00:02.0 1:DIS: :Off:0000:01:00.0IGD就是集成显卡,DIS是独立显卡。Pwr为通电的显卡,off为关掉的显卡。加号为正在使用的显卡。以下操作需要在 root 权限下进行。但是如果不需要切换显卡,只是切断电源,可以直接进行最后一步然后重启。切换到独立显卡echo DDIS > /sys/kernel/debug/vgaswitcheroo/switch切换到集成显卡echo DIGD > /sys/kernel/debug/vgaswitcheroo/switch关闭不使用的显卡echo OFF > /sys/kernel/debug/vgaswitcheroo/switch搞定之后,在 rc.local 上添加最后一个,开机自动关闭不用的显卡CPU情况有的博客推荐jupiter,我的源里没有,懒得找所以用了 cpufreqd,效果也是扛扛的。sudo apt-get install cpufreqd它支持情景模式,配置 /etc/cpufreqd.conf。里面已经有样例了,可以仿照它自己定义。下面的是我的设置,懒得自己改的可以复制粘贴。# this is a comment # see CPUFREQD.CONF(5) manpage for a complete reference # # Note: ondemand/conservative Profiles are disabled because # they are not available on many platforms. [General] pidfile=/var/run/cpufreqd.pid poll_interval=2 verbosity=4 #enable_remote=1 #remote_group=root [/General] #[acpi] #acpid_socket=/var/run/acpid.socket #[/acpi] #[nforce2_atxp1] #vcore_path=/some/path #vcore_default=1500 #[/nforce2_atxp1] #[sensors_plugin] #sensors_conf=/some/file #[/sensors_plugin] #[Profile] #name=On Demand High #minfreq=40% #maxfreq=100% #policy=ondemand #[/Profile] # #[Profile] #name=On Demand Low #minfreq=20% #maxfreq=80% #policy=ondemand #[/Profile] [Profile] name=Performance High minfreq=100% maxfreq=100% policy=performance #exec_post=echo 8 > /proc/acpi/sony/brightness [/Profile] [Profile] name=Performance Low minfreq=80% maxfreq=80% policy=performance [/Profile] [Profile] name=Powersave High minfreq=60% maxfreq=60% policy=powersave [/Profile] [Profile] name=Powersave Low minfreq=40% maxfreq=40% policy=powersave [/Profile] #[Profile] #name=Conservative High #minfreq=33% #maxfreq=100% #policy=conservative #[/Profile] # #[Profile] #name=Conservative Low #minfreq=0% #maxfreq=66% #policy=conservative #[/Profile] ## # Basic states ## # when AC use Conservative mode [Rule] name=AC Rule ac=on # (on/off) profile=Conservative High [/Rule] # stay in Conservative mode for the first minutes [Rule] name=AC Off - High Power ac=off # (on/off) battery_interval=70-100 #exec_post=echo 5 > /proc/acpi/sony/brightness profile=Conservative Low [/Rule] # conservative mode when not AC [Rule] name=AC Off - Medium Battery ac=off # (on/off) battery_interval=30-70 #exec_post=echo 3 > /proc/acpi/sony/brightness profile=Powersave High [/Rule] # conservative mode when not AC [Rule] name=AC Off - Low Battery ac=off # (on/off) battery_interval=0-30 #exec_post=echo 3 > /proc/acpi/sony/brightness profile=Powersave Low [/Rule] ## # Special Rules ## # CPU Too hot! [Rule] name=CPU Too Hot acpi_temperature=55-100 cpu_interval=50-100 profile=Conservative Low [/Rule] # use performance mode if I'm watching a movie # I don't care for batteries! # But don't heat too much. [Rule] name=Movie Watcher programs=xine,mplayer,gmplayer battery_interval=0-100 acpi_temperature=0-60 cpu_interval=0-100 profile=Performance High [/Rule]
-
如何正确学习 JavaScript 正确学习 JavaScript(写给非 JavaScript 程序员和编程新手)原文:How to Learn JavaScript Properly(2014-2-7)学习时长:6~8周学习前提:中学水平,无需编程经验更新(2014-1-7)在 Reddit 上创建了一个学习小组January 2014, “Learn JavaScript” Study Group on Reddit目录 不要这样学习JavaScript 本课程资源 第1-2周(简介,数据类型,表达式和操作符) 第3-4周(对象,数组,函数,DOM,jQuery) JavaScript终极编辑器:WebStorm 第一个项目-动态问答应用 第5-6周(正则表达式,Window对象,事件,jQuery) 第7周,可延长到8周(类,继承,HTML5) 继续提升 一些鼓励的话 上面的课程大纲提供了一个结构化和富有启发性的学习线路,从初学者到有所建树,把JavaScript学对学透。既然你找到这篇文章来,说明你是真心想学好JavaScript的。你没有想错,当今如果要开发现代网站或web应用(包括互联网创业),都要学会JavaScript。而面对泛滥的JavaScript在线学习资源,却是很难找到一份高效而实用的方法去学习这个“web时代的语言”。有一点需要注意,几年前我们需要知道一个真正的服务器端语言(比如PHP,Rails,Java,Python 或者 Perl)去开发可扩展,动态的,数据库驱动的web应用,而现在只用JavaScript就可以实现了。不要这样学习JavaScript不要一开始就埋头在成堆的JavaScript在线教程里 ,这是最糟糕的学习方法。或许在看过无数个教程后会有点成效,但这样不分层次结构地学习一个东西实在是十分低效,在实际用JavaScript建立网站或web应用时你还是会频繁的卡住。总的来说,这种学习方法会让人不知道如何将语言当做工具来使用——当做个人工具来用。另外,也许有人会建议从尊敬的JavaScript教父Douglas Crockford写的《JavaScript语言精粹》开始学习JavaScript。然而,虽然Crockford先生对JavaScript无所不知,被誉为JavaScript世界的爱因斯坦,但他的《JavaScript语言精粹》并不适合初学者学习。这本书没有通透、清晰、明了的阐述JavaScript的核心概念。但对于更高级的学习路线,我倒会建议你看看Crockford先生的视频。还有,不要只从Codecademy等网站学习JavaScript,因为即使知道怎么编写一大堆JavaScript代码小片段,还是不能学会怎么建立一个web应用程序。即便如此,在后面我还是会建议把Codecademy当做补充的学习资源。本课程资源更新:Reddit用户d0gsbody4月8号在Reddit上建立了一个学习小组。他和其他组员都非常积极和乐于助人。我建议你加入这个小组,他们会让你保持积极性且帮助你更好的学习JavaScript。毕竟独自折腾JavaScript还是有点难度的。链接:Learning JS Properly – Study Group on Reddit 请在以下两本书中选一本,第一本比较适合有编程经验的人,而另一本则适合完全没有编程经验的初学者。我个人推荐第一本书,因为作者对各个知识点都阐述得非常好且涵盖了一些高级JavaScript知识点。但是,要看懂这本书你至少要对web开发有一定的基本了解。所以,如果你有一点点编程经验或者web开发经验(不一定是JavaScript),那就买这本书吧。 纸质版(英文) :Professional JavaScript for Web Developers 纸质版(中文) :JavaScript高级程序设计(第3版) Kindle版(英文):Professional JavaScript for Web Developers Kindle版(中文):JavaScript高级程序设计(第3版) 如果你没有编程经验,可以买这本: 纸质版(英文) :JavaScript: The Definitive Guide 纸质版(中文) :JavaScript权威指南(第6版) Kindle版(英文):JavaScript: The Definitive Guide Kindle版(中文):JavaScript权威指南(原书第6版) 免费注册Stack Overflow,这是一个编程领域的问答论坛。在这里提问题得到的回答比Codecademy要好,哪怕你的问题非常基础,看起来很傻(记住,从来没有愚蠢的问题)。 免费注册Codecademy,这是一个在线学习平台,你可以直接在浏览器里面写代码。 JavaScriptIsSexy上的一些博文,包括对象,闭包,变量的作用域和提升,函数等等。 JavaSctipt学习路线完成整个课程大纲需要花上6~8周的时间,将学会完整的JavaScript语言(包括jQuery和一些HTML5)。如果你没有时间在6个星期里完成所有的课程(确实比较有挑战性),尽量不要超过8个星期。花的时间越长,掌握和记忆各种知识点的难度就越大。第1-2周(简介,数据类型,表达式和操作符) 如果你还不是很了解HTML和CSS,完成Codecademy上的web基础任务。 阅读《JavaScript权威指南》或者《JavaScript高级程序设计》的前言和第1~2章。 十分重要:在书中遇到的每个样例代码都要动手敲出来并且在火狐或Chrome浏览器控制台中跑起来、尽量蹂躏它(做各种试验)。也可以用jsfiddle,但不要用Safari浏览器。我建议用火狐搭配Firebug插件去测试和调试代码。浏览器控制台就是可以让你编写和运行JavaScript代码的地方。 完成Codecademy JavaScript Track上的Introduction to JavaScript部分。 阅读《JavaScript权威指南》第3~4章。 或者阅读《JavaScript高级程序设计》第3~4章。你可以跳过位操作部分,在你的JavaScript生涯中一般不会用上这个。再次说明,记得要不时停下来把书本的代码敲到浏览器控制台里(或者JSFiddle)做各种测试,可以改变几个变量或者把代码结构修改一番。 阅读《JavaScript权威指南》第5章。至于《JavaScript高级程序设计》则暂时没有阅读任务,因为前面已经把相关知识覆盖了。 完成Codecademy JavaScript Track上的2~5部分。 第3-4周(对象,数组,函数,DOM,jQuery) 以下三选一: 阅读我的博文JavaScript 对象详解. 阅读《JavaScript权威指南》第6章。 阅读《JavaScript高级程序设计》第6章。注意:只需要看“理解对象”(Understanding Objects)部分。 两本书会涉及更多的一些细节,但只要看完我的博文,你可以完全放心地跳过这些细节。 阅读《JavaScript权威指南》第7~8章或者《JavaScript高级程序设计》第5和7章。 此时,你应该花大量时间在浏览器控制台上写代码,测试if-else语句,for循环,数组,函数,对象等等。更重要的是,你要锻炼和掌握独立写代码,不用借助Codecademy。在Codecademy上做题时,每个任务对你来说应该都很简单,不需要点帮助和提示。 如果你还卡在Codecademy上,继续回到浏览器上练习,这是最好的学习方法。就像詹姆斯年轻时在邻居的篮球场上练球,比尔盖茨在地下室里学习编程。持续地练习,这一点点的进步积累起来效果会非常惊人。你要看到这个策略的价值,相信它是可行的,全心投入进去。Codecademy会造成已掌握的错觉。使用Codecademy最大的问题是,它的提示和代码小片段会让人很容易就把答案做出来,造成一种已经掌握这个知识点的错觉。你可能一时看不出来,但这样做你的代码就不是独立完成的了。但目前为止,Codecademy依然是学习编程的好帮手。特别是从一些基本的代码结构如if语句,for循环,函数和变量去指导你了解小项目和小应用的开发过程。 回到Codecademy完成JavaScript路线。做完6~8部分(数据结构做到Object 2)。 实现Codecademy上Projects路线的5个基础小项目(Basic Projects)。做完之后,你已不再需要Codecademy了。这是一件好事,因为自己做的越多,学得就越快,就能更好准备开始独立编程。 阅读《JavaScript权威指南》第13,15,16和19章。 或者阅读《JavaScript高级程序设计》第8,9,10,11,13和14章。这本书没有涉及到jQuery,而Codecademy上的jQuery知识也覆盖得不够。可以看看jQuery的官方教程,免费的:http://try.jquery.com/你也可以在《JavaScript权威指南》第19章了解更多的jQuery知识。 完成全部的jQuery教程http://try.jquery.com/。 JavaScript终极编辑器:WebStorm 在你实现第一个项目之前,如果打算以后做JavaScript开发者或者经常用到JavaScript,最好现在就去下载WebStorm的试用版。这里可以学习怎么使用WebStorm(专门为这个课程写的)。毋庸置疑,WebStorm是JavaScript编程最好的编辑器(或IDE)。30天试用后要付$49.00,但作为JavaScript开发者,这应该是除了买书以外最明智的投资了。 确保在WebStorm中启用JSHint。JSHint是一个检查JavaScript代码错误和潜在问题的工具,强制你的团队按照规范写代码。用WebStorm最爽的地方是JSHint会自动在错误的代码下显示红线,就像文字处理程序中的拼写检查。JSHint会显示一切的代码错误(包括HTML),促使你养成良好的习惯,成为更好的JavaScript程序员。这很重要,当你真正意识到WebStrom和JSHint对你的巨大帮助时,你会回来感谢我的。 此外,WebStorm是一个世界级,专业人员使用的IDE,用来编写专业的JavaScript web应用,所以你以后会经常用到它。它还结合了Node.js,Git和其它JavaScript框架,所以即使你成为了明星级的JavaScript开发者,你还是会用到它的。除非以后出现了更多的JavaScript IDE。 公平起见,我在这里提一下Sublime Text 2,这是仅次于WebStorm的JavaScript编辑器。它的功能不及WebStorm丰富和完整(即使添加了一堆插件)。做小修改的时候我会用到Sublime Text 2,它支持很多语言,包括JavaScript,但我不会用它来构建完整的JavaScript Web应用。 第一个项目-动态问答应用此时,你已经掌握了足够的知识去建立一个稳固的,可维护的web应用。在做完我为你设计的这个应用之前不要看后面的章节。如果你卡住了,去Stack Overflow提问并且把书上相关的内容重新看一遍直到完全理解这些概念。接下来开始建立一个JavaScript问答应用(还会用到HTML和CSS),功能如下: 这是一套单选测试题,完成之后会显示用户的成绩。 问答应用可以产生任意多的问题,每个问题可以有任意多的选项。 在最后的页面显示用户的成绩。这个页面只显示成绩,所以要把最后一个问题去掉。 用数组存所有的问题。每个问题包括它的选项和正确答案,都封装成一个对象。问题数组看起来应该是这样: // 这里只演示一个问题,你要把所有问题都添加进去 var allQuestions = [ { question: "Who is Prime Minister of the United Kingdom?", choices: [ "David Cameron", "Gordon Brown", "Winston Churchill", "Tony Blair"], correctAnswer: 0 } ]; 当用户点击“Next”时,使用document.getElementById或jQuery动态的添加下一个问题,并且移去当前问题。在这个版本里“Next”是唯一的导航按钮。 你可以在本文下方评论求助,最好是去Stack Overflow提问,在那里会有及时而准确的回答。 第5-6周(正则表达式,Window对象,事件,jQuery) 阅读《JavaScript权威指南》第10,14,17,20章。或者阅读《JavaScript高级程序设计》第20,23章。 记得要把样例代码敲到浏览器控制台上,尽可能蹂躏它,做各种测试,直到完全理解它是怎么工作,它能干些什么。 此时,你用起JavaScript来应该很顺手,有点像武林高手要出山了。但你还不能成为高手,你要把新学到的知识反复使用,不停的学习和提升。 升级之前做的问答应用 添加客户端数据验证:保证用户回答了当前问题才能进入下个问题。 添加“Back”按钮,允许用户返回修改答案。最多可以返回到第一个问题。注意对于用户回答过的问题,选择按钮要显示被选中。这样用户就无需重新回答已经答过的问题。 用jQuery添加动画(淡出当前问题,淡入下个问题) 在IE8和IE9下测试,修改bug,这里应该会有得你忙了。 ;D 把问题导出JSON文件 添加用户认证,允许用户登陆,把用户认证信息保存在本地存储(local storage,HTML5浏览器存储)。 使用cookies记住用户,当用户再次登陆时显示“欢迎用户名回来”。 第7周,可延长到8周(类,继承,HTML5) 阅读《JavaScript权威指南》第9,18,21,22章。或者阅读我的博文JavaScript面向对象必知必会或者阅读《JavaScript高级程序设计》第6,16,22,24章,第6章只读“创建对象”(Object Creation)和“继承”(Inheritance)部分。注意:这部分是本课程中技术性强度最大的阅读,要根据自身的状况考虑要不要全部读完。你至少要知道原型模式(Prototype Pattern),工厂模式(Factory Pattern)和原型继承(Prototypal Inheritance),其它的不作要求。 继续升级你的问答应用: 页面布局使用Twitter Bootstrap,把问答的元素弄得看起来专业一些。而作为额外奖励,用Twitter Bootstrap的标签控件(译者注:原文地址失效,已改)显示问题,每个标签显示一个问题。 学习Handlebars.js,将Handlebars.js模板用在问答应用上。你的JavaScript代码中不应该再出现HTML代码了。我们的问答应用现在越来越高级啦。 记录参加问答的用户成绩,展示用户在问答应用中与其他用户的排名比较。 在学完Backbone.js和Node.js后,你会用这两种最新的JavaScript框架重构问答应用的代码,使之变成复杂的单页面现代web应用。你还要把用户的认证信息和成绩保存在MongoDB数据库上。 接下来:构思一个项目,趁热打铁迅速的去开发。卡住的时候参考《JavaScript权威指南》或者《JavaScript高级程序设计》。当然,还要成为Stack Overflow的活跃用户,多问问题,也要尽量回答其它人的提问。 继续提升 精通backbone.js 中高级JavaScript进阶 不侧漏精通Node.js Meteor.js入门(即将出炉) 三个最好的JavaScript前端框架(即将出炉) 一些鼓励的话祝你学习顺利,永不放弃!当你做不下去觉得自己很蠢的时候(你会时不时这么想的),请记住,世界各地的其他初学者,甚至是有经验的程序员,也会不时产生这种想法的。如果你是完全的初学者,特别是过了青少年时期的人,开始写代码的时候也许很困难。年轻人无所畏惧,也没有什么负担,他们可以花大量的时间在喜欢的东西上。所以各种挑战对他们来说也不过是短暂的障碍罢了。但过了青少年期后你会希望快速的见到成效。因为你没有这么多的时间去花上几个小时就为了搞清楚一些细节的东西。但这些东西你必须深入去理解它,不要因此沮丧,坚持完成课程的任务,把bug都找出来,直到你完全理解。当你到达胜利的彼岸时,你会知道这一切都是值得的,你会发现编程非常有趣而且在上面花的时间都会得到可观的回报。一个人必须去感受和领悟构建程序带来的强烈快感。当你一步步的掌握知识点,一点点的将程序搭建起来时,就会对自己产生激励与肯定,带来十分美妙的满足感。总有一天你会意识到之前忍受的所有困难都是值得的。因为你将要成为一名光荣的程序员,你也清楚作为JavaScript开发者,你的前途一片光明。就像在你之前成千上万的程序员一样,你打败了最难的bug,你没有退步,你没有放手,你没有找任何借口让自己放弃。当你学有所成的时候,放心的将你的成果分享给我们吧,哪怕是个微不足道的,小到显微镜都看不到的小项目。 ;D
-
不侧漏精通 Node.js 原文:Learn Node.js Completely and with Confidence(2013-2-4)学习时长:约2周学习前提:JavaScript 知识掌握 5/10要成为 JavaScript 开发者现在是最好的时机了,而且会越来越好。主要是因为 HTML5 的来临, Flash 的逝去,移动设备的普及,以及最重要的 Node.js —— 开发者终于可以在服务器端使用 JavaScrpit 了。Node.js 本身是革命性的,它已经非常接近未来的现代 web 开发 —— 纯 JavaScript 作为服务器端语言。我将为你提供一条详细的 Node.js 学习路线,对我来说很有效(我用 Node.js 开发的一个电子商务 web app),我相信对你也适用。你将完全学会 Node.js,要自信地走完这个课程,因为2~3个星期后你将可以在短时间内建立一个超快,实时的 web 应用了。为什么学习 Node.jsJavaScript 已经成为当今的 web 语言,而且毫无疑问未来的几年都会保持这个地位,因为还没有出现 JavaScript 的替代品。ECMAScript 组织正在全速推进 JavaScript 语言。而且 Node.js 的出现使到开发者可以在服务器端使用纯 JavaScript 开发现代 web 应用。完全了解 Node.js 之后,你将可以开发实时,快速,可扩展,数据驱动的 web 应用;你将有必备的知识去快速适应任何新型,前沿的 JavaScript 框架,如 Derby.js 和 Meter.js。值得注意的是,几年前我们需要知道一个真正的服务器端语言(比如PHP,Rails,Java,Python 或者 Perl)去开发可扩展,动态的,数据库驱动的web应用,而现在只用JavaScript就可以实现了。不要这样学习 Node.js 现在已有数不清的 Node.js 教程,但大部分都不能用来精通 Node.js,更不用说去判断哪个教程好了。大部分教程都不能满足你完全学会 Node.js 所需要的深度和结构。一年前我学习 Node.js 的时候看了一大堆 Node.js 教程,在一些教程中浪费了不少时间。有的教程让人非常失望(我一点实质性的东西都没学到),白折腾让我很沮丧。我愿意在这里点出那些没用的教程或者贴出它们网址,但我只想说,不要在那些教程上浪费你的时间了。我深信还有很多优秀的 Node.js 教程,但你需要移开一堆普通教程才能找到最好的。这样学习 Node.js 效率不高。我这样走过来了,所以我希望这个教程可以帮到你,让你不用浪费我曾浪费的时间。 不要在亚马逊上根据评论去挑一本 Node.js 书。即便这是挑书的常用方法(我的书就是这么买的),但因为 Node.js 还是一个新的平台,大部分的书都没有足够大的评论样本让你来评估它的实用性和价值。简而言之就是这些评论还不够好。如过在亚马逊上搜索“Node.js”,你会发现至少有21本 Node.js 的书。虽然我只读过当中的4本(最好的4本),我发现坏书存在一个模式:作者似乎对 Node.js 体系结构和平台都没有一个深入广泛的理解,而书本仿佛就是一堆普通教程的集合体。我读的4本 Node.js 书中,有两本不错,但我打算只推荐其中一本。这两本书是《Node.js高级编程》(Professional Node.js: Building JavaScript Based Scalable Software),作者 Pedro Teixera;和《了不起的Node.js: 将JavaScript进行到底》(Smashing Node.js: JavaScript Everywhere),作者 Guillermo Rauch。我推荐前者,但是从后者中你也可以学到不少,所以两本都买吧,如果你非常重视 Node.js 开发的话。 重要说明书评在我写这篇文章的时候,《Node.js高级编程》在亚马逊上只有两个评论。一个评价很好(5颗星),而另一个是差评 —— 你最好自己看一下。这就是那个差评:我不知道这本书写得好还是坏,因为它的排版太差了,有很多地方根本看不了。显然,这个评论者没有看过这本书而且他的评论都是关于排版的问题,我倒没发现。我会给这本书5颗星,因为这是目前我读过最好的 Node.js 书。但我不是从亚马逊买的,所以我没有在那里作评论。而且声明一下我跟本文中推荐的两个作者都不认识。资源 《Node入门》(The Node Beginner Book),作者Manuel Kiessling。这本书很薄,但真的是 Node.js 教程。这本书跟另外一本书$9.99捆绑销售,《Hands-on Node.js》,作者是前面提到的 Pedro Teixeira。但有趣的是,我并不觉得捆绑的这本书好用,所以你不需要它,我们也不会用它来学习 Node.js。但既然买两本书才$9.99,就一起买吧。 《Node.js高级编程》,作者 Pedro Teixera 中文版 英文版 精通 Node.js 路线 如果你 JavaScript 已经学得非常好,敲起 JavaScript 代码时觉得自己屌炸天了,请直接跳到第2点。如果你的 JavaScript 知识不足以让你用原生 JavaScript 开发一个完整的交互式问答应用。你应该正确学习 JavaScript如果你的 JavaScript 基础还行,只是想温习一下,可以按顺序读一读下面三篇文章: JavaScript 对象详解 JavaScript 变量作用域与提升解释 (必读)轻松掌握 JavaScript 闭包 阅读《Node.js高级编程》第1章,按照指示在你的电脑上配置好 Node.js。 阅读《Node入门》整本,这本书很小的,基本上就是个教程。它会给你进行简单的介绍并让你对 Node.js 开发环境涉及的东西有一个基本的了解。在阅读《Node.js高级编程》其它部分之前读读这个,作为一个好的开始。 阅读《Node.js高级编程》第2章。 阅读链接 CommonJS 部分,不用读完整篇文章。 阅读《Node.js高级编程》第3~6章。 阅读《Node.js高级编程》第7~15章。 可选:如果你买了《了不起的Node.js》,阅读第8~9章。 阅读《Node.js高级编程》第17~22章。 读完《Node.js高级编程》。 现在你已经有足够的 Node.js 知识去建立一个现代 web 应用的后端了,你最好学习 Backbone.js 来迅速开发 web 应用前端。只会 Node.js 的话你只能算是 Node.js 开发者,但学会 Backbone.js 和 Node.js,你就是一个屌炸天的 JavaScript 开发者,拥有建立各种 web 应用的技能和工具了。去精通backbone.js。 精通了 Node.js 与 Backbone.js 后你已经可以开发任意类型的 web 应用了。你现在就可以开始开发点什么了,如果够大胆的话。但在你的冒险开始之前,先将下面链接的 NodeApp web 应用建出来;这个练习为你提供了一个现实使用的 Node.js/Backbone.js web 应用开发:http://dailyjs.com/web-app.html 进阶学习:你还需要学习两个技术来帮助巩固你的 Node.js 和 Backbone.js 技能:Handlebars.js 模板与 MongoDB 数据库。事实上,你在 Backbone.js 中就接触过 Underscore.js 模板,在上面第10步时就已学了一点 MongoDB 知识。但你还要学习 Handlebars 因为它比 Underscore.js 模板引擎的鲁棒性更好,功能更丰富。读读我的Handlebars.js 教程。你还要学会用 MongoDB 建立复杂的应用。我将会再写一篇关于 MongoDB 的博文。 祝你好运并且保持专注直到你完成整个课程:永不放弃。而且注意不要用超过3周的时间完成这个课程。