搜索到
1061
篇与
的结果
-
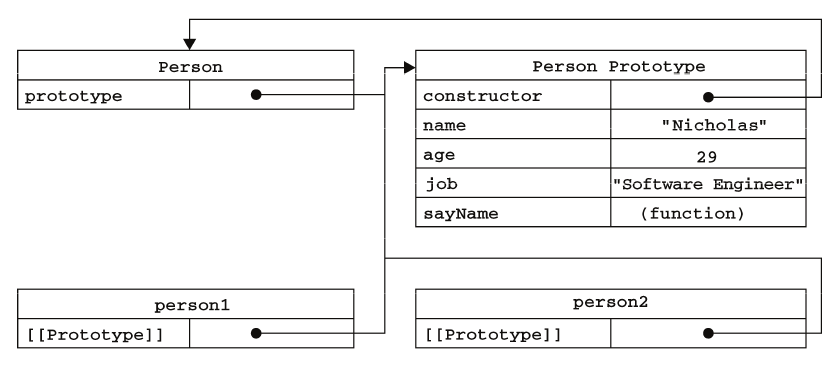
 JavaScript 创建对象总结 JavaScript 是一门灵活的语言,就创建对象而言就有各种各样的方法。本文是《JavaScript高级程序设计》(第3版)的笔记,主要是针对各种创建对象方法之间的关系、优缺点进行梳理。每种方法相关的其它细节不是本文重点,我会标记页码。创建单个对象1、object 构造函数:调用 Object 的构造函数。person 的 constructor 值是 Object。var person = new Object(); person.name = 'StrayBugs'; person.age = 22; person.job = 'student'; person.sayName = function() { alert(this.name); };2、字面量:不会调用 Object 的构造函数。而 person 的 constructor 值也是 Object。var person = { name: 'StrayBugs', age: 22, job: 'student', sayName: function() { alert(this.name); } }优点:简单、方便缺点:批量创建对象很麻烦。不能使用 instanceof 来确定对象类型(都是 Object)。工厂模式工厂模式是为了解决批量创建对象的问题。就是用一个函数将上述创建单个对象的方法包装起来,就可以减少代码量了。以第一种方法为例:function createPerson(name, age, job) { var o = new Object(); o.name = name; o.age = age; o.job = job; o.sayName = function() { alert(this.name); }; return o; } var person1 = createPerson('StrayBugs', 22, 'student'); var person2 = createPerson('Angel', 20, 'Artist');优点:减少了代码量。缺点:未能解决对象识别的问题。构造函数模式构造函数模式解决了对象识别问题,是基于工厂模式的改进。是利用了 new 作用域转移的特性。function Person(name, age, job) { this.name = name; this.age = age; this.job = job; this.sayName = function() { alert(this.name); }; } var person1 = new Person('StrayBugs', 22, 'student'); var person2 = new Person('Angel', 20, 'Artist');必须用 new 操作符来创建 Person 实例。以这种方式调用构造函数实际上会经历以下4个步骤: 创建一个新对象; 将构造函数的作用域赋给新对象(因此 this 就指向了这个新对象); 执行构造函数中的代码(为这个新对象添加属性); 返回新对象。 此时 person1 与 person2 都可以用 constructor 和 instanceof 来验证其对象类型是 Person。当不使用 new 来创建对象时,由于在全局作用域中 this 指向 Global(浏览器中就是 window 对象),所以可以直接通过 window 对象调用 sayName,不建议这么做,会污染全局环境。也可以用 call() 与 apply() 来为 Person 指定作用域。优点:在工厂模式的基础上解决了对象识别问题。缺点:每个实例的方法都是独立的,多数情况下同个对象的实例方法都是一样的,于是这里造成了冗余。偏方:将函数定义单独出来,如下面例子:function Person(name, age, job) { this.name = name; this.age = age; this.job = job; this.sayName = sayName; } function sayName() { alert(this.name); }; var person1 = new Person('StrayBugs', 22, 'student'); var person2 = new Person('Angel', 20, 'Artist');这么写是不是很别扭,也没有封装性可言。原型模式原型模式很好解决了上面的封装性问题。原型也是 JavaScrip 最重要的特性之一。书本篇幅比较长,这里只为了突出原型要解决的问题,所以会省略很多。原型就是为了共用而生:默认情况下,每个对象与它的所有实例都共用一个原型。对象可以通过 .prototype 访问原型。实例存在内部属性 [[Prototype]],不能直接访问(不推荐使用 __proto__)。function Person() { } Person.prototype.name = 'StrayBugs'; Person.prototype.age = 22; Person.prototype.job = 'student'; Person.prototype.sayName = function() { alert(this.name); }; var person1 = new Person(); person1.sayName(); //"StrayBugs" var person2 = new Person(); person2.sayName(); //"StrayBugs" alert(person1.sayName == person2.sayName); //true原型也可以用字面量来创建,但是其 constructor 要手动修改,具体方法及副作用见书 P155。如下图,原型的 constructor 属性指向 Person,Person 的两个实例的 [[Prototype]] 直接指向原型,与 Person 没有直接关系。上图可以看到三者是共用同一个原型。于是 Person 在原型上的改变会影响到所有的实例。Person.prototype.sayName = function() { alert("hi!"); }; person1.sayName(); //"hi!" person2.sayName(); //"hi!"注意当实例上存在与原型重名的属性时,实例的属性会屏蔽掉原型的属性。因为先是查看实例中有无该属性,没找到才会去原型中查找。书本 P150。对象还可以重写原型,但此时已创建的实例依然指向旧原型(前面说了实例原型与对象无直接关系)。书本 P157优点:共用原型减少了冗余。缺点:在原型上的改变会影响到所有的实例,于是实例没有了独立性。组合使用构造函数模式和原型模式目的是解决原型模式的独立性问题。将需要共用的属性(一般是方法)定义在原型上,将独立的属性定义在构造函数中。function Person(name, age, job){ this.name = name; this.age = age; this.job = job; this.friends = ["Shelby", "Court"]; } Person.prototype = { constructor : Person, sayName : function(){ alert(this.name); } }; var person1 = new Person('StrayBugs', 22, 'student'); var person2 = new Person('Angel', 20, 'Artist'); person1.friends.push("Van"); alert(person1.friends); //"Shelby,Count,Van" alert(person2.friends); //"Shelby,Count" alert(person1.friends === person2.friends); //false alert(person1.sayName === person2.sayName); //true优点:结合了构造函数模式和原型模式的优点,并解决了其缺点。缺点:代码没有很好的封装起来。动态原型模式看到这里也应该猜到,动态原型模式就是为了解决上面的封装问题。function Person(name, age, job){ //属性 this.name = name; this.age = age; this.job = job; //方法 if (typeof this.sayName != "function"){ Person.prototype.sayName = function(){ alert(this.name); }; } } var friend = new Person('StrayBugs', 22, 'student'); friend.sayName(); //'StrayBugs'这里即使有多个方法也只需判断其中一个方法存不存在即可开始初始化。到了这里其实最后两种创建对象的方法已经非常完美了。接下来讲的是一些特殊情况下,上面都不适应时的方法。寄生构造函数模式顾名思义,有时候我们需要在一些已有的对象上添加一些方法,但是又不能(或不希望)改变该对象的构造函数,就可以用寄生构造函数模式。function createPerson(name, age, job) { var o = new Object(); o.name = name; o.age = age; o.job = job; o.sayName = function() { alert(this.name); }; return o; } var person1 = new createPerson('StrayBugs', 22, 'student'); var person2 = new createPerson('Angel', 20, 'Artist');它的定义方法跟工厂模式一模一样,不同的是调用时使用 new 创建。这是因为虽然里面都是 o,工厂模式中的 o 是作为实例,所以返回的是实例。寄生构造函数模式中的 o 是作为构造函数,所以返回的是构造函数。下面的例子更贴切。function SpecialArray(){ //创建数组 var values = new Array(); //添加值 values.push.apply(values, arguments); //添加方法 values.toPipedString = function(){ return this.join("|"); }; //返回数组 return values; } var colors = new SpecialArray("red", "blue", "green"); alert(colors.toPipedString()); //"red|blue|green"这样就在 Array 的基础上建立了新的构造函数了。缺点:与工厂模式一样,不能依赖 instanceof 操作符来确定对象类型。稳妥构造函数模式主要是为了在安全执行环境中使用。P161稳妥构造函数遵循与寄生构造函数类似的模式,但有两点不同:一是新创建对象的实例方法不引用 this;二是不使用 new 操作符调用构造函数。function Person(name, age, job){ //创建要返回的对象 var o = new Object(); //可以在这里定义私有变量和函数 //添加方法 o.sayName = function(){ alert(name); }; //返回对象 return o; } 这里除了使用 sayName() 方法之外,没有其他办法访问 name 的值。可以像下面使用稳妥的 Person 构造函数。var friend = Person('StrayBugs', 22, 'student'); friend.sayName(); //'StrayBugs'缺点:与寄生构造函数一样,不能依赖 instanceof 操作符来确定对象类型。总结以上五花八门的创建对象方式正体现了 JavaScript 的灵活性。这里没有好与差的方法,只有最适合的方法。我认为重点是把这几种方法串起来,因为如果不了解其 WHAT HOW WHY,不仅很容易就忘记了,而且不能清晰的了解在什么场合适合运用什么方法。所以希望有机会能看到这篇文章的同学以后不用再愁“对象问题”啦!
JavaScript 创建对象总结 JavaScript 是一门灵活的语言,就创建对象而言就有各种各样的方法。本文是《JavaScript高级程序设计》(第3版)的笔记,主要是针对各种创建对象方法之间的关系、优缺点进行梳理。每种方法相关的其它细节不是本文重点,我会标记页码。创建单个对象1、object 构造函数:调用 Object 的构造函数。person 的 constructor 值是 Object。var person = new Object(); person.name = 'StrayBugs'; person.age = 22; person.job = 'student'; person.sayName = function() { alert(this.name); };2、字面量:不会调用 Object 的构造函数。而 person 的 constructor 值也是 Object。var person = { name: 'StrayBugs', age: 22, job: 'student', sayName: function() { alert(this.name); } }优点:简单、方便缺点:批量创建对象很麻烦。不能使用 instanceof 来确定对象类型(都是 Object)。工厂模式工厂模式是为了解决批量创建对象的问题。就是用一个函数将上述创建单个对象的方法包装起来,就可以减少代码量了。以第一种方法为例:function createPerson(name, age, job) { var o = new Object(); o.name = name; o.age = age; o.job = job; o.sayName = function() { alert(this.name); }; return o; } var person1 = createPerson('StrayBugs', 22, 'student'); var person2 = createPerson('Angel', 20, 'Artist');优点:减少了代码量。缺点:未能解决对象识别的问题。构造函数模式构造函数模式解决了对象识别问题,是基于工厂模式的改进。是利用了 new 作用域转移的特性。function Person(name, age, job) { this.name = name; this.age = age; this.job = job; this.sayName = function() { alert(this.name); }; } var person1 = new Person('StrayBugs', 22, 'student'); var person2 = new Person('Angel', 20, 'Artist');必须用 new 操作符来创建 Person 实例。以这种方式调用构造函数实际上会经历以下4个步骤: 创建一个新对象; 将构造函数的作用域赋给新对象(因此 this 就指向了这个新对象); 执行构造函数中的代码(为这个新对象添加属性); 返回新对象。 此时 person1 与 person2 都可以用 constructor 和 instanceof 来验证其对象类型是 Person。当不使用 new 来创建对象时,由于在全局作用域中 this 指向 Global(浏览器中就是 window 对象),所以可以直接通过 window 对象调用 sayName,不建议这么做,会污染全局环境。也可以用 call() 与 apply() 来为 Person 指定作用域。优点:在工厂模式的基础上解决了对象识别问题。缺点:每个实例的方法都是独立的,多数情况下同个对象的实例方法都是一样的,于是这里造成了冗余。偏方:将函数定义单独出来,如下面例子:function Person(name, age, job) { this.name = name; this.age = age; this.job = job; this.sayName = sayName; } function sayName() { alert(this.name); }; var person1 = new Person('StrayBugs', 22, 'student'); var person2 = new Person('Angel', 20, 'Artist');这么写是不是很别扭,也没有封装性可言。原型模式原型模式很好解决了上面的封装性问题。原型也是 JavaScrip 最重要的特性之一。书本篇幅比较长,这里只为了突出原型要解决的问题,所以会省略很多。原型就是为了共用而生:默认情况下,每个对象与它的所有实例都共用一个原型。对象可以通过 .prototype 访问原型。实例存在内部属性 [[Prototype]],不能直接访问(不推荐使用 __proto__)。function Person() { } Person.prototype.name = 'StrayBugs'; Person.prototype.age = 22; Person.prototype.job = 'student'; Person.prototype.sayName = function() { alert(this.name); }; var person1 = new Person(); person1.sayName(); //"StrayBugs" var person2 = new Person(); person2.sayName(); //"StrayBugs" alert(person1.sayName == person2.sayName); //true原型也可以用字面量来创建,但是其 constructor 要手动修改,具体方法及副作用见书 P155。如下图,原型的 constructor 属性指向 Person,Person 的两个实例的 [[Prototype]] 直接指向原型,与 Person 没有直接关系。上图可以看到三者是共用同一个原型。于是 Person 在原型上的改变会影响到所有的实例。Person.prototype.sayName = function() { alert("hi!"); }; person1.sayName(); //"hi!" person2.sayName(); //"hi!"注意当实例上存在与原型重名的属性时,实例的属性会屏蔽掉原型的属性。因为先是查看实例中有无该属性,没找到才会去原型中查找。书本 P150。对象还可以重写原型,但此时已创建的实例依然指向旧原型(前面说了实例原型与对象无直接关系)。书本 P157优点:共用原型减少了冗余。缺点:在原型上的改变会影响到所有的实例,于是实例没有了独立性。组合使用构造函数模式和原型模式目的是解决原型模式的独立性问题。将需要共用的属性(一般是方法)定义在原型上,将独立的属性定义在构造函数中。function Person(name, age, job){ this.name = name; this.age = age; this.job = job; this.friends = ["Shelby", "Court"]; } Person.prototype = { constructor : Person, sayName : function(){ alert(this.name); } }; var person1 = new Person('StrayBugs', 22, 'student'); var person2 = new Person('Angel', 20, 'Artist'); person1.friends.push("Van"); alert(person1.friends); //"Shelby,Count,Van" alert(person2.friends); //"Shelby,Count" alert(person1.friends === person2.friends); //false alert(person1.sayName === person2.sayName); //true优点:结合了构造函数模式和原型模式的优点,并解决了其缺点。缺点:代码没有很好的封装起来。动态原型模式看到这里也应该猜到,动态原型模式就是为了解决上面的封装问题。function Person(name, age, job){ //属性 this.name = name; this.age = age; this.job = job; //方法 if (typeof this.sayName != "function"){ Person.prototype.sayName = function(){ alert(this.name); }; } } var friend = new Person('StrayBugs', 22, 'student'); friend.sayName(); //'StrayBugs'这里即使有多个方法也只需判断其中一个方法存不存在即可开始初始化。到了这里其实最后两种创建对象的方法已经非常完美了。接下来讲的是一些特殊情况下,上面都不适应时的方法。寄生构造函数模式顾名思义,有时候我们需要在一些已有的对象上添加一些方法,但是又不能(或不希望)改变该对象的构造函数,就可以用寄生构造函数模式。function createPerson(name, age, job) { var o = new Object(); o.name = name; o.age = age; o.job = job; o.sayName = function() { alert(this.name); }; return o; } var person1 = new createPerson('StrayBugs', 22, 'student'); var person2 = new createPerson('Angel', 20, 'Artist');它的定义方法跟工厂模式一模一样,不同的是调用时使用 new 创建。这是因为虽然里面都是 o,工厂模式中的 o 是作为实例,所以返回的是实例。寄生构造函数模式中的 o 是作为构造函数,所以返回的是构造函数。下面的例子更贴切。function SpecialArray(){ //创建数组 var values = new Array(); //添加值 values.push.apply(values, arguments); //添加方法 values.toPipedString = function(){ return this.join("|"); }; //返回数组 return values; } var colors = new SpecialArray("red", "blue", "green"); alert(colors.toPipedString()); //"red|blue|green"这样就在 Array 的基础上建立了新的构造函数了。缺点:与工厂模式一样,不能依赖 instanceof 操作符来确定对象类型。稳妥构造函数模式主要是为了在安全执行环境中使用。P161稳妥构造函数遵循与寄生构造函数类似的模式,但有两点不同:一是新创建对象的实例方法不引用 this;二是不使用 new 操作符调用构造函数。function Person(name, age, job){ //创建要返回的对象 var o = new Object(); //可以在这里定义私有变量和函数 //添加方法 o.sayName = function(){ alert(name); }; //返回对象 return o; } 这里除了使用 sayName() 方法之外,没有其他办法访问 name 的值。可以像下面使用稳妥的 Person 构造函数。var friend = Person('StrayBugs', 22, 'student'); friend.sayName(); //'StrayBugs'缺点:与寄生构造函数一样,不能依赖 instanceof 操作符来确定对象类型。总结以上五花八门的创建对象方式正体现了 JavaScript 的灵活性。这里没有好与差的方法,只有最适合的方法。我认为重点是把这几种方法串起来,因为如果不了解其 WHAT HOW WHY,不仅很容易就忘记了,而且不能清晰的了解在什么场合适合运用什么方法。所以希望有机会能看到这篇文章的同学以后不用再愁“对象问题”啦! -
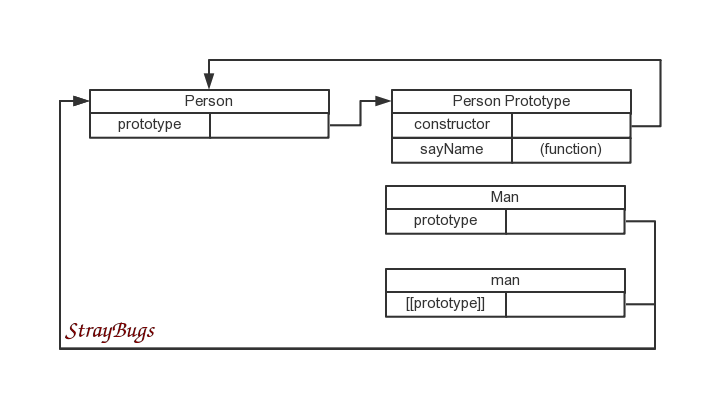
JavaScript 继承总结 先用一个简单的 Person 类作为文章其它例子的前提。function Person(name) { if(name !== undefined) { this.name = name; } else { this.name = "StrayBugs"; } this.age = 22; } Person.prototype.sayName = function() { alert(this.name); };原型链JavaScript 中实现继承第一个方法是利用原型链。继承就是要让子类获得父类的属性和方法。原型链的思路是利用原型共享的特点,让父类的一个实例充当子类的原型。父类的实例必然包括了父类的属性与方法,那么子类的所有实例都可以通过原型链一层层找到父类的属性与方法了。新手很可能会在这里混淆,请分析出下面三种代码中原型与实例的属性与方法。function Man() { } //第一种 Man.prototype = Person; var man = new Man(); //第二种 Man.prototype = Person(); var man = new Man(); //第三种 Man.prototype = new Person(); var man = new Man();第一种:Man.prototype 获得的是 Person 函数的指针,也就是说,Man.prototype 就是 Person 函数。这里没有任何调用 Man.prototype 的代码,且 Man 是个空函数,所以其实例 man 的内部属性 [[prototype]] 值指向 Person 函数。第二种:构造函数本质也是函数。Person() 相当于执行了构造函数并将返回值赋给原型。因为 Person() 没有 return,故返回值为 undefined,于是代码等价于 Man.prototype = undefined;,所以 man 的 [[prototype]] 值为 Object。第三种:正解。创建了一个 Person 实例,有了属性与方法。Man 的所有实例将共享这个 Person 实例。原型链的缺点与创建对象的原型模式一样,适合用来继承方法,不适合继承属性。因为一般情况下我们都希望各个实例的属性值是独立的。而且,因为属性是共用的,大家的值都一样,无法针对某个实例去初始化。借用构造函数与创建对象的思路类似,这里对应构造器模式的是借用构造函数(Constructor Stealing)技术。就是在子类的构造函数中通过 父类.apply(this) 或者 父类.call(this) 来借用父类构造器。这时每个实例都有单独的副本,互不影响,所以可以在构造函数中传入参数进行初始化。function Man(name) { //每个实例都可以有自己的名字 Person.call(this, name); //子类增加的属性 this.job = 'student'; } var man1 = new Man(); var man2 = new Man('Jesse'); alert(man1.name); //"StrayBugs" alert(man2.name); //"Jesse" alert(man1.sayName); //undefined alert(man2.sayName); //undefined其缺点与构造函数模式一样,没有继承原型链,方法没有共享。组合继承参考创建对象的“组合使用构造函数模式和原型模式”,这里也可以组合构造函数与原型链来实现继承,叫做组合继承(Combination Inheritance)。是 JavaScript 中最常用的继承模式。function Man(name) { //每个实例都可以有自己的名字 Person.call(this, name); //子类增加的属性 this.job = 'student'; } //继承方法 Man.prototype = new Person(); Man.prototype.constructor = Man; //子类增加的方法 Man.prototype.sayAge = function() { alert(this.age); }; var man1 = new Man(); var man2 = new Man('Jesse'); man1.sayName(); //"StrayBugs" man2.sayName(); //"Jesse" man2.sayAge(); //22 alert(man1 instanceof Man); //true alert(man1 instanceof Person); //true alert(man1.constructor.prototype.isPrototypeOf(man2)); //true可以看到 instanceof 与 isPrototypeOf 都可以正常工作。再画个图加深理解。可以看到,这个方法还是有点小缺陷。就是子类的原型上还保留了一份无用的共用属性。原型式继承原型式继承(Prototypal Inheritance)很特别,它希望利用现有的对象去继承该对象的类。说白了,就是前文的原型链继承那里,将 new Person() 换成一个现有的对象(比如 Person的一个现有的实例)。封装起来就是这个样子:function object(o) { function F() {} F.prototype = o; return new F(); }可以看到,原理上是跟原型链一样的,可以看做是原型链的简化版,在只需简单地浅复制一个对象时很有用。但同时要注意原型的潜在问题,如下面的例子:var person = new Person(); var man = object(person); man.name = 'Jesse'; man.sayName(); //"Jesse" alert(man.age); //22 person.name = 'StrayBugs'; person.age = 101; man.sayName(); //"Jesse" alert(man.age); //101ECMAScript5 新增 Object.create() 方法规范化了原型式继承。寄生式继承这时你也许会想,可不可以在原型式继承的基础上再添加方法?当然可以,这就是寄生式继承(Parasitic Inheritance),且寄生式继承不局限于原型式继承。顾名思义,这里可以联想起寄生构造函数模式,也就是工厂模式的变种。寄生式继承可以看做是原型式继承的增强版。function createMan(person) { //这里不一定是 object(),可以是任意能返回新对象的函数 var man = object(person); man.sayAge = function() { alert(this.age); }; return man; } var person = new Person(); var man = createMan(person); man.sayAge(); //22这里也可以看到,寄生式继承对象的方法没有复用。寄生组合式继承前面组合继承结尾的时候提了一下,子类的原型上会保留了一份无用的属性。这是因为使用组合继承会调用两次父类构造函数。第一次调用是为子类添加原型 new Person() 的时候,第二次是子类构造函数内部调用 Person.call(this, name) 。寄生组合式继承解决了这个问题。第一次调用构造函数的目的就是为了得到父类的原型,那么有了原型式继承的浅复制方法,我们就可以直接复制原型了嘛。function inheritPrototype(Man, Person) { //只复制原型 var p = object(Person.prototype); p.constructor = Man; Man.prototype = p; }定义:function Man(name) { Person.call(this, name); this.job = 'student'; } inheritPrototype(Man, Person); Man.prototype.sayAge = function() { alert(this.age); };抛开这个函数去看其实就是原型链继承中将 new Person() 换成 object(Person.prototype)。 instanceof 与 isPrototypeOf 对 Person 依然有效。var man = new Man('Jesse'); man.sayAge(); //22 alert(man instanceof Man); //true alert(man instanceof Person); //true alert(Man.prototype.isPrototypeOf(man)); //true alert(Person.prototype.isPrototypeOf(man)); //true再画个图加深理解,跟原型链比较。总结可见原型几乎贯穿了各种 JavaScript 继承方式。理解以及灵活利用原型是写出优秀代码的关键。无论是继承还是创建对象,最终理想的方案都是将几种不同方式的优点结合在一起,这正是 JavaScript 灵活的魅力。
-
深入理解 JavaScript 模块模式 拜读 2010 年神文,原文:JavaScript Module Pattern: In-Depth(2010-03-12)模块模式(module pattern)是一种常见的 JavaScript 编程模式,大家一般都能很好地熟悉掌握。但其实这里还有不少高级用法没有得到关注。本文将带大家回顾一些基础知识,然后介绍一些值得关注的高级用法,包括一个我认为是我首创的用法。基础知识我们先简单介绍一下模块模式,自从 Eric Miraglia (就职于 YUI)三年前(2007)的一篇博文中提出后便广为人知。如果你已经熟悉模块模式,完全可以放心地跳到高级模式。匿名闭包这是使后面所有技术成为可能的基础,也是 JavaScript 最好的唯一一个特性。我们只需简单地创建一个匿名函数,然后立即执行。函数中所有的代码都会存在于一个闭包当中;闭包在应用的整个生命周期内都会为其代码提供隐私和状态保护。(function () { // ... 所有的变量和函数都只在这个作用域中 // 依然能保持对所有全局的访问 }());注意括住匿名函数的 ()。这是语言所要求的,因为 function 开头的语句会被翻译成函数声明,加上括号后就变成了函数表达式。全局导入JavaScript 有一个称为隐式全局变量(implied globals)的特性。当一个名字被使用的时候,解析器会顺着作用域链由里往外一层层查找该名字的变量声明。如果没有找到,这个变量就默认是全局的。如果是在赋值语句中使用且没有找到,就会自动创建一个全局变量。这意味着在匿名闭包中很容易就能使用或创建全局变量。然而,这样的代码会变得难以管理,因为对人来说很难判断哪些变量是全局的。值得高兴的是,匿名函数为此提供了一个很好的解决方案。通过将全局变量作为参数传入匿名函数,就相当于将其导入(import)到我们代码中,比起隐式全局变量此方法既简洁又高效。看例子:(function ($, YAHOO) { //现在可以在这段代码中访问全局的 jQuery (作为 $) 和 YAHOO }(jQuery, YAHOO));模块导出有时候我们不仅要使用全局变量,还希望能声明全局变量。这时只需要简单的将它们导出即可,利用匿名函数的返回值。到这里就是模块模式的所有基础内容了,看完整的例子:var MODULE = (function () { var my = {}, privateVariable = 1; function privateMethod() { // ... } my.moduleProperty = 1; my.moduleMethod = function () { // ... }; return my; }());注意这里我们声明了一个 MODULE 全局模块。它带有两个属性:一个 MODULE.moduleMethod 方法和一个 MODULE.moduleProperty 变量。此外它还在匿名函数中利用闭包维持了一个私有内部状态(private internal state)。而且我们还能方便地导入所需模块,利用回前面刚讲的知识。高级模式尽管前面提到的方法已足够应付多数场景,我们还是可以在模块上更进一步创造一些强大的、可扩展的结构。接下来我们把这些方法逐个看一遍,继续用回前面的 MODULE 模块。模块扩展前面讲的模块模式有一个局限性,即整个模块必须在一个文件里。有大型代码库工作经验的人都知道分割多文件的各种好处。幸运的是,有一个不错的方法可以实现模块扩展:先导入模块,然后添加属性,再把它导出来。看下面的样例,对之前实现的 MODULE 模块进行扩展:var MODULE = (function (my) { my.anotherMethod = function () { // 增加方法... }; return my; }(MODULE));这里是为了样例代码一致性才使用了 var 关键字,其实可以不要。这段代码运行后 MODULE 就得到了一个公开的方法 MODULE.anotherMethod。这个扩展文件也会保持其自身的私有内部状态和导入。松耦合扩展前面的例子需要模块创建部分先运行,然后再跑扩展部分代码;其实顺序是可以不限的。JavaScript 程序在性能上的一个优点就是异步加载脚本。我们可以按任意顺序创建模块的各个部分然后通过松耦合扩展(Loose Augmentation)灵活地加载到一起。每个文件都应该按如下结构创建:var MODULE = (function (my) { // 增加功能... return my; }(MODULE || {}));这里的 var 关键字是必需的。注意到导入的时候只有 MODULE 还不存在时才会去创建模块。这方法意味着可以用 LABjs 之类的工具并行加载所有模块文件,无需进行阻塞。紧耦合扩展松耦合扩展虽然好用,但还是会给模块带来一定局限性。其中最重要一点是无法安全重写模块属性;也不能在初始化过程中使用其它文件的模块属性(初始化完成后才可以)。紧耦合扩展(Tight Augmentation)要按一定顺序加载,但好处是允许重写。这里有个简单的例子(被扩展的是前面最原始的 MODULE):var MODULE = (function (my) { var old_moduleMethod = my.moduleMethod; my.moduleMethod = function () { // 重写方法,可以通过 old_moduleMethod 访问旧的方法... }; return my; }(MODULE));例子重写了 MODULE.moduleMethod,且按需可以保持原来方法的引用。克隆与继承var MODULE_TWO = (function (old) { var my = {}, key; for (key in old) { if (old.hasOwnProperty(key)) { my[key] = old[key]; } } var super_moduleMethod = old.moduleMethod; my.moduleMethod = function () { // 重写克隆对象的方法,同时通过 super_moduleMethod 访问父类 }; return my; }(MODULE));此模式恐怕是灵活性最低的选择。它的确给予了一些巧妙的成分,却是以牺牲灵活性为代价。属性如果是对象或函数在这里是不会被复制的,只会变成两个引用指向同个对象。利用其中一个引用进行修改另一个也会受到影响。对于对象来说,可以利用递归克隆解决这个问题;但函数就不行了,除非用 eval 或许还可以。虽然这模式不是那么地好用,但为了完整性我还是提了一下它。跨文件私有状态将模块分成多文件的一个严重局限性是每个文件只能保持其自身的私有状态,无法访问其它文件的私有状态。这个有解决办法。下面的例子是一个松耦合扩展模块,其保持的私有状态跨越了所有的扩展:var MODULE = (function (my) { var _private = my._private = my._private || {}, _seal = my._seal = my._seal || function () { delete my._private; delete my._seal; delete my._unseal; }, _unseal = my._unseal = my._unseal || function () { my._private = _private; my._seal = _seal; my._unseal = _unseal; }; // 可永久访问 _private, _seal, 和 _unseal return my; }(MODULE || {}));所有文件都可以在其局部变量 _private 中设置属性,其它文件立即就可以使用。在模块加载完成后,程序应该调用 MODULE._seal() 阻止外部代码访问内部的 _private。在模块的生命周期里如果需要再次扩展模块,只需在加载新文件之前,先让任意文件中的一个内部方法调用 _unseal() 开放权限,执行完扩展后再调用 _seal() 封闭。这个模式是我今天工作时突然想到的,我还没有在其它地方见过。我认为这个模式很有用,值得在这里一提。子模块最后一个高级模式其实是最简单的。有许多创建子模块的好例子,跟创建普通模块一样:MODULE.sub = (function () { var my = {}; // ... return my; }());尽管这里比较显浅,但我觉得还是有必要提一下的。子模块拥有普通模块所有的高级功能,包括扩展和私有状态。结论大部分的高级模式都可以互相结合,以创造出更有用的模式。如果要我主张一条路线来设计复杂的应用,我会结合松耦合扩展,私有状态和子模块。本文我一直都没有提过性能,但我想在这里简单说一下:模块模式的性能表现很好。它显著地减少了代码量,加快了代码下载速度;使用松耦合扩展允许简单的非阻塞并行下载,也加快了下载速度。初始化耗时可能比其它方法慢一点点,但还是值得的。运行时性能只要全局变量正确导入就不会有什么问题,甚至会因使用局部变量表示子模块减短了引用链而得到加速。最后再介绍一个子模块,它可以动态加载到父模块(没有父模块就会创建一个)。为了简单明了我没有加入私有状态,要加上去也很简单。此模式允许整个复杂的分层代码库完全并行地加载自身、子模块等等。var UTIL = (function (parent, $) { var my = parent.ajax = parent.ajax || {}; my.get = function (url, params, callback) { // 好吧,这个方法是有点坑爹,呵呵 :) return $.getJSON(url, params, callback); }; // 等等... return parent; }(UTIL || {}, jQuery));希望本文能帮到你,记得在评论里分享你的想法哦!现在勇往直前,写出更好、更模块化的 JavaScript 吧!
-
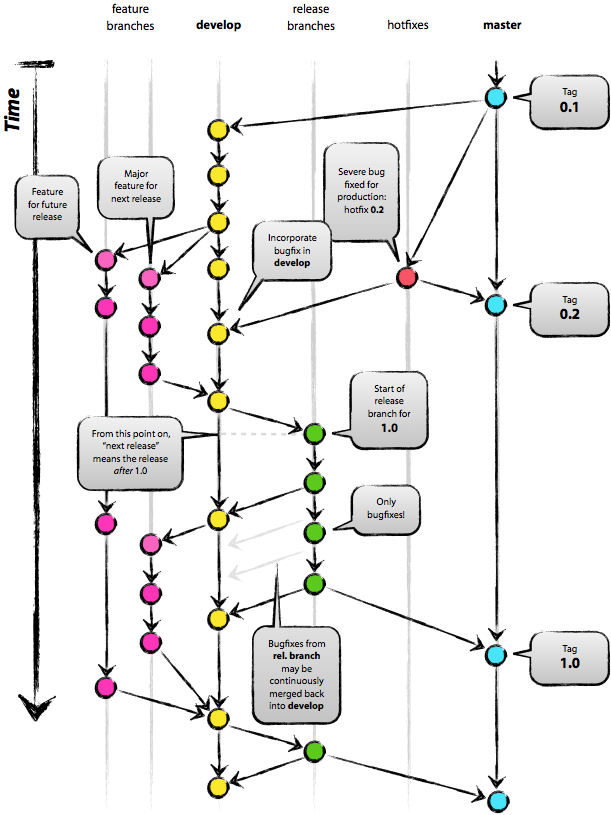
Git 分支模式笔记 正想了解 Git 开发流程方面的资料,就碰上了这篇 2010 年的好文。没有时间翻译,就做一下笔记。主要内容可以看到,该模型分支的组成主要有 5 种类型: master develop release feature hotfix 开发主要在 develop 上做,稳定版本释放由 develop 派生 release 分支。发布一段时间确定可以后,就合并回 develop 和 master 并打 tag。若以后 master 出现问题需要修改,就派生 hotfix 分支修复,最后合并回 master 和 develop。feature 派生自 develop,主要是尝试新特性。成功的话合并回 develop。下面是各个分支的细节:主要分支(The main branches)主要分支是 master 和 develop 分支。约定 origin/master 上的 HEAD 总是代表“生产就绪(production-ready)状态”。约定 origin/develop 上的 HEAD 总是代表“下一个 release 的最新开发进展”。具体怎么从 develop 合并到 master 在 release 分支中会讲到。辅助分支(Supporting branches)辅助分支是 feature、release 和 hotfix 分支。feature 分支可能派生自:develop必须合并到:develop分支命名惯例:除了 master, develop, release-* 或 hotfix-* 的其它名字feature 分支一般不会出现在 origin 中。如果尝试失败的话甚至不会合并到 develop 分支中。1、创建 feature 分支,从 develop 分支中派发:$ git checkout -b myfeature develop Switched to a new branch "myfeature"2、成功的 feature 分支最终合并回 develop 分支:$ git checkout develop Switched to a new branch "develop" $ git merge --no-ff myfeature Updating ea1b82a..05e9557 (Summary of changes) $ git branch -d myfeature Deleted branch myfeature (was 05e9557) $ git push origin develop--no-ff 会阻止 Git 进行 fast-farward(下图右),并在 develop 分支上产生新的结点标识 feature 分支的合并。这么做以后更容易回头查看变更。release 分支可能派生自:develop必须合并到:develop 与 master分支命名惯例:release-*当为本次发布的功能(几乎)都完成了之后,就可以派生 release 分支等待正式发布。可以在 release 分支上做些小修复。其它的修改最好提到下次的发布上。1、创建分支,第一时间就要修改版本号:$ git checkout -b release-1.2 develop Switched to a new branch "release-1.2" $ ./bump-version.sh 1.2 Files modified successfully, version bumped to 1.2. $ git commit -a -m "Bumped version number to 1.2" [release-1.2 74d9424] Bumped version number to 1.2 1 files changed, 1 insertions(+), 1 deletions(-)bump-version.sh 是虚构的一个脚本用来在项目相关文件上修改版本号。2、真正发布后,合并到 master 分支上并打 tag$ git checkout master Switched to branch 'master' $ git merge --no-ff release-1.2 Merge made by recursive. (Summary of changes) $ git tag -a 1.23、如果 release 分支上修改了 bug,则也要合并会 develop 分支,注意版本号文件可能会冲突:$ git checkout develop Switched to branch 'develop' $ git merge --no-ff release-1.2 Merge made by recursive. (Summary of changes)4、删除 release 分支$ git branch -d release-1.2 Deleted branch release-1.2 (was ff452fe).hotfix 分支可能派生自:master必须合并到:develop 与 master分支命名惯例:hotfix-*hotfix 与 release 一样也会产生新的 tag,只不过 hotfix 分支是被动出现的。1、创建分支,记得提升版本号$ git checkout -b hotfix-1.2.1 master Switched to a new branch "hotfix-1.2.1" $ ./bump-version.sh 1.2.1 Files modified successfully, version bumped to 1.2.1. $ git commit -a -m "Bumped version number to 1.2.1" [hotfix-1.2.1 41e61bb] Bumped version number to 1.2.1 1 files changed, 1 insertions(+), 1 deletions(-)2、提交修复$ git commit -m "Fixed severe production problem" [hotfix-1.2.1 abbe5d6] Fixed severe production problem 5 files changed, 32 insertions(+), 17 deletions(-)3、确定可以后合并回 master 分支,记得打 tag$ git checkout master Switched to branch 'master' $ git merge --no-ff hotfix-1.2.1 Merge made by recursive. (Summary of changes) $ git tag -a 1.2.14、再合并回 develop 分支$ git checkout develop Switched to branch 'develop' $ git merge --no-ff hotfix-1.2.1 Merge made by recursive (Summary of changes)5、删除 hotfix 分支$ git branch -d hotfix-1.2.1 Deleted branch hotfix-1.2.1 (was abbe5d6).
-
CSS Font 单位 了解 CSS font 各个单位的意义,搜了一些资料。[1]绝对单位 cm (centimeter 厘米) mm (millimeter 毫米) in (inch 英寸) pt (point 点) pc (pica 派卡) 相对单位 em (em = 目标元素像素值 / 父元素 font-size 的像素值) [3] ex (约为小写字母 a, c, m, o 之类的高度) [1] px (pixel 像素) em有的文章(书)会提到 em 是指大写字母 M 的宽度([4] P57)。那是已经过时的说法,现在很多字体的 M 其实占不到 1em 的宽度。[2]只用 em 和 px例子来自 www.w3.org0.5pt, 1px, 1pt, 1.5px, 2px如果前面四根线看起来一样(或者 0.5pt 的看不见了),你应该是在用不能显示小于 1px 点的电脑显示屏。如果能看到线的厚度递增,你应该在看高质量电脑显示器或打印的纸张。如果 1pt 看起来比 1.5px 厚,你可能在用手持设备。当需要排列文字与图片的时候用 px 比较合适。而字体更好是用 em 。(一)不要设置 body 的 font 大小,因为默认大小是读者可以舒适阅读的大小。(二)用 em 设置其它元素大小,比如 2.5em 就是 body 字体的 2.5 倍大小。只有在设置打印字体的时候才用 pt/cm/in 单位。新型单位 rem (root em 就是依据根元素字体大小的比值,em 会叠加,rem 不会) vw (window 宽度的 1/100) vh (window 高度的 1/100) 参考 www.w3.org wikipedia developer.mozilla.org 《CSS设计指南(第3版)》