搜索到
1205
篇与
的结果
-
 如何实现一个楼中楼的评论系统 1. 实现前的思考 # 在经历过多说和网易云跟帖后,总算是下定决心自己要写一个评论系统了。我们在使用的很多评论系统中,目前比较流行的就是楼中楼的方式了,比如百度贴吧,wordpress 等等。在这以前,一般都是按照时间顺序进行 1 楼、2 楼、3 楼的展示,如果要回复某个人,使用@符号标识出这个用户的名字,然后回复内容。可是这样存在一个很大的问题,讨论问题没有集中在一起,其他用户根本不知道你们在讨论什么,原作者在 1 楼发表评论,你进来回复这个用户的评论时,已经到 10 楼了,原作者再回复你又到 20 楼了。其他用户看到 10 楼时,早已经忘记原作者说了什么了。百度贴吧在改版之前就是这种方式,后来在新版中启用了楼中楼的方式,这种方式,关于某个话题的讨论就能集中在一块了。同时,知乎也对他的评论系统进行了一次改版,不过不是改版成楼中楼,而是在每个有对话评论的后面加上一个弹窗链接查看对话,点击链接后弹窗能看到这两个人之间互动的所有评论。采用时间顺序倒序或者正序平铺的方式展示评论,这种方式实现起来简单,但是阅读困难;采用楼中楼的方式展示评论,对用户的阅读习惯比较友好,但是实现起来可能比较困难。不过,最后仍然决定采用楼中楼的方式来,虽然本人博客的评论量也少的可怜,不过还是决定要实现一下。 2. 数据表的设计 # 先说下前后端使用的语言和框架,前端考虑到页面渲染和比较多的事件调用,使用了 vue 框架,vue 应该说不是最好的选择,毕竟对一个评论的前端部门来说,可能有点大材小用,不过为了快速开发,也就选择了 vue。后端使用的是 php 语言,数据库使用的是 mysql。数据库表的设计,既要考虑到可以导入以前的数据,又能方便以后添加新的评论。这里我创建了 3 个表: 文章表,用户表,评论表。在网易云跟帖关闭之前,我把自己的数据导出来了(多说的数据已经丢失,不知道导出的格式是什么了),我们来看下网易云跟帖里导出数据的格式:{ "title": "从0到1学习node(七)之express搭建简易论坛", "url": "www.xiabingbao.com/node/2017/02/20/node-express-forum.html", "sourceId": "", "ctime": 1487581007000, "comments": [ { "cid": "72813956", "ctime": 1493107384000, "content": "这个论坛对node 的版本有要求吗 我的node比较老 下载你的源码 访问出错", "pid": "0", "ip": "xxx", "port": 0, "sc": "web", "vote": 0, "against": 0, "anonymous": false, "user": { "userId": "1074123", "nickname": "有态度网友06q23q", "avatar": "", "anonymous": false } }, { "cid": "77196403", "ctime": 1493714822000, "content": "不太清楚,我这里node版本是6.9.4,npm版本是3.10.10,你试一下升级node版本", "pid": "72813956", "ip": "xxx", "port": 0, "sc": "web", "vote": 0, "against": 0, "anonymous": false, "user": { "userId": "2414123", "nickname": "小小dd蚊子", "avatar": "http://cms-bucket.nosdn.127.net/1d6faddedb544cee93ff426a4aa2fe7620170322162349.jpg", "anonymous": false } } ] } 从上面的数据里,可以看到,每个文章都有标题,url 和评论,评论的每一项都有自己对应的 id,其回复的评论 pid,内容 content,该评论的用户 userid, nickname 和 avatar。我这里也就只摘取主要的信息录入到数据库中。 2.1 用户表 # 用户表相对来说比较简单,要考虑的就是原有的 userid 也要作为字段进行保存,方便在导入评论数据时能找到对应的用户,在评论数据也导入完成后即可将该字段删除,以后新添加的注册用户用不到这个字段了。用户表的设计: 字段 类型 说明 id int 自增,主键 wid int 用户原有的 userid nickname varchar(50) 昵称 avatar varchar(100) 头像 status int 状态 设计好用户表后,将原数据中所有的用户都单独拿出来,然后使用 userid 作为 key 存储到一个数组中,这样也能起到一个去重的效果。把拿到的所有的用户数据存储到用户表 2.2 评论表 # 在设计评论表,主要考虑如下的因素: 评论必须依托于文章和用户才能存在,因此评论的外键是文章标识和 userid,留言板是一个文章内容为空的评论形式; 我想以后新的评论能使用自增 id,而不是跟随原有评论的 cid 来产生新的评论 id,因此这次评论表的主键是 id,原有的评论 id 只作为其中的一个字段 wid 来构造楼中楼的关系,这些旧评论插入到数据表时都会有新的评论 id; 楼中楼的评论是处在某个评论下的,同时,楼中楼里还有相互之前的互动回复。因此这个评论的 pid(parentid)表示当前评论处于哪个评论之下,同时 replyid 表示是回复的哪个评论;若直接回复的父级评论,则 pid 与 replyid 相同,都是父级评论的 id,若回复的不是父级评论,则 pid 为父级评论的 id,replyid 为回复评论的 id;pid 或 replyid 为 0 时,则表示直接对文章发表评论。 因此我们的评论表是这样设计的: 字段 类型 说明 id int 自增,主键 wid int 评论原有的主键 cid uid int 用户 id replyid int 该评论回复的评论 id,没有则为 0 pid int 该评论所在的父级 id,没有则为 0 aid varchar(100) 文章的标识 content varchar(300) 评论内容 createtime int 评论时间的时间戳 表中的 aid(文章的标识)可以是文章的 url,文章的 id 或者其他任何能够唯一识别该文章的东东都可以。这里我们使用的是文章的 uri 来作为唯一标识,比如上面数据中的文章,我们使用/node/2017/02/20/node-express-forum.html来标识文章。其他文章同理。将这些评论写入表时,我们还要注意的是,原数据中,每个评论都对应着一个用户,在我设计的系统里,用户与评论分来了,只使用 uid 来进行关联。新的用户与新的评论都是使用自有的自增主键,因此在原有评论进行入库时,需要将原来的 userid 转换为新用户表中的主键 id,新旧数据进行统一。文章表不做解释。 3. 具体实现 # 前端部分主要是负责展示每个文章的评论,同时让登录用户可以添加评论。 3.1 展示评论 # 我们已经对每个评论都添加了文章标识,前端只要根据 aid 就能拿到当前文章所有的评论。不过我们的评论是要楼中楼的方式展示的,不能一股脑的把数据平铺到页面中。我们在 2.2 中也说了,pid 为 0 的评论都是直接对文章进行评论的,这些评论应该是作为一级评论展示的;pid 为其他数据的,必然是属于某个评论之下,应当作为楼中楼展示。同时,无论一级评论,还是楼中楼的评论,都有可能产生分页的情况,因此这里也要做好分页处理。那么最终,我们前端拿到的结构应该大致是这样的:{ "code": 0, "data": [ { // 一级评论 "id": 1, "content": "蚊子的博客棒棒的", "createtime": "2017年08月08日00:26", "nickname": "匿名者", "reply": { // 楼中楼 "data": [ { "id": 1, "content": "谢谢,一起学习", "createtime": "2017年08月08日00:36", "nickname": "蚊子" } ], "page": { "cur_page": 1, "all_page": 1 } } } ], "page": { "cur_page": 1, "all_page": 1 } } 前端拿到接口返回的数据后,就可以渲染页面了。在头像的处理上,也考虑到了 https 的环境,因此返回的头像链接都是//开头的形式。 3.2 参与评论 # 用户对文章或者某个评论产生了共鸣,需要留言讨论一番,我们就需要用户能够把自己的评论也添加进去。评论的类型,细分的话,可以分为 3 类: 直接对文章发表评论,pid 与 replyid 为空; 对一级评论进行回复,pid 与 replyid 均为一级评论的 id; 对楼中楼进行回复,pid 为一级评论的 id,replyid 为你回复的评论的 id 我这里前端的实现参考了 oschina(开源中国)的评论方式。直接对文章评论,是直接在顶部的评论窗口进行输入;对其他评论进行回复时,采用弹窗的方式来进行回复。弹窗回复的好处就是,页面不用滚动,用户对某个评论的感知也能停留在这个位置;同时也不用增加各种不必要的小输入框来让用户输入评论。 3.3 登录 # 在登录问题上,我也是纠结了不少的时间,究竟是使用自己的登录系统呢,还是使用第三方登录呢,或者是用户不用注册登录,只要输入邮箱和昵称就能进行评论呢?使用自己的评论系统,那么就需要开发一套注册和登录流程,开发麻烦,而且对于想要回复一句话的用户来说,可能就直接放弃注册了;若只要输入邮箱和昵称就能评论,我考虑到可能会引起用户的无限评论,无法控制。因此,最后还是考虑接入第三方的登录,这里选择了使用微博作为第三方登录的入口,后续会考虑加入 github 的帐号登录。关于如何接入微博的第三方登录,我们下篇文章再讲,文档齐全,对不熟悉的开发者来说,刚开始可能有点懵逼,不过应该问题不大。 3.4 添加邮箱功能 # 用户在第三方登录成功后,在名字旁边有个小的 input 输入框,可以让用户输入邮箱来接收回复提醒,这个输入完全是自愿的,不输入邮箱也依然可以评论。也是考虑到本站是个小站,访问量极低,用户可能一时兴起评论了两句,事后又想起这个网站来,又不知道怎么找了。因此就想着添加一个邮件提醒功能,不让大神的评论石沉大海。 3.5 特别注意 # 在刚开始实现完成评论功能的时候,用户只要进到这个页面,评论就会加载。但是有个问题就是,用户不一定会把你的文章看到底部,不一定就看你的评论。因此后来文章就改成了按需加载,只有用户滚动到底部,有想要看评论的意向时采取加载评论。最终展示的效果就是这样: 4. 总结 # 作为一名前端开发,用仅有的后端知识开发一套博客的评论系统,显得是非常的简陋,整个框架的设计感觉也是很糙。同时缓存系统用的不熟练,不能做到评论信息的立即更新。这个系统依然还有很多改进的地方。欢迎大家对蚊子多多提意见和建议。在写这篇文章的时候,想着是以后要改版的时候,可以做成评论同步加载的方式进行。生成后的文章,更新频率极低,甚至不太变动,那么缓存的就是评论的内容,每当有新的评论时,就删除当前文章的缓存,重新加载新的数据,然后再缓存上新的数据,这样在评论数据更新比较低的时候,可以缓存的时间更长,同时也有利于搜索引起对评论内容的抓取。
如何实现一个楼中楼的评论系统 1. 实现前的思考 # 在经历过多说和网易云跟帖后,总算是下定决心自己要写一个评论系统了。我们在使用的很多评论系统中,目前比较流行的就是楼中楼的方式了,比如百度贴吧,wordpress 等等。在这以前,一般都是按照时间顺序进行 1 楼、2 楼、3 楼的展示,如果要回复某个人,使用@符号标识出这个用户的名字,然后回复内容。可是这样存在一个很大的问题,讨论问题没有集中在一起,其他用户根本不知道你们在讨论什么,原作者在 1 楼发表评论,你进来回复这个用户的评论时,已经到 10 楼了,原作者再回复你又到 20 楼了。其他用户看到 10 楼时,早已经忘记原作者说了什么了。百度贴吧在改版之前就是这种方式,后来在新版中启用了楼中楼的方式,这种方式,关于某个话题的讨论就能集中在一块了。同时,知乎也对他的评论系统进行了一次改版,不过不是改版成楼中楼,而是在每个有对话评论的后面加上一个弹窗链接查看对话,点击链接后弹窗能看到这两个人之间互动的所有评论。采用时间顺序倒序或者正序平铺的方式展示评论,这种方式实现起来简单,但是阅读困难;采用楼中楼的方式展示评论,对用户的阅读习惯比较友好,但是实现起来可能比较困难。不过,最后仍然决定采用楼中楼的方式来,虽然本人博客的评论量也少的可怜,不过还是决定要实现一下。 2. 数据表的设计 # 先说下前后端使用的语言和框架,前端考虑到页面渲染和比较多的事件调用,使用了 vue 框架,vue 应该说不是最好的选择,毕竟对一个评论的前端部门来说,可能有点大材小用,不过为了快速开发,也就选择了 vue。后端使用的是 php 语言,数据库使用的是 mysql。数据库表的设计,既要考虑到可以导入以前的数据,又能方便以后添加新的评论。这里我创建了 3 个表: 文章表,用户表,评论表。在网易云跟帖关闭之前,我把自己的数据导出来了(多说的数据已经丢失,不知道导出的格式是什么了),我们来看下网易云跟帖里导出数据的格式:{ "title": "从0到1学习node(七)之express搭建简易论坛", "url": "www.xiabingbao.com/node/2017/02/20/node-express-forum.html", "sourceId": "", "ctime": 1487581007000, "comments": [ { "cid": "72813956", "ctime": 1493107384000, "content": "这个论坛对node 的版本有要求吗 我的node比较老 下载你的源码 访问出错", "pid": "0", "ip": "xxx", "port": 0, "sc": "web", "vote": 0, "against": 0, "anonymous": false, "user": { "userId": "1074123", "nickname": "有态度网友06q23q", "avatar": "", "anonymous": false } }, { "cid": "77196403", "ctime": 1493714822000, "content": "不太清楚,我这里node版本是6.9.4,npm版本是3.10.10,你试一下升级node版本", "pid": "72813956", "ip": "xxx", "port": 0, "sc": "web", "vote": 0, "against": 0, "anonymous": false, "user": { "userId": "2414123", "nickname": "小小dd蚊子", "avatar": "http://cms-bucket.nosdn.127.net/1d6faddedb544cee93ff426a4aa2fe7620170322162349.jpg", "anonymous": false } } ] } 从上面的数据里,可以看到,每个文章都有标题,url 和评论,评论的每一项都有自己对应的 id,其回复的评论 pid,内容 content,该评论的用户 userid, nickname 和 avatar。我这里也就只摘取主要的信息录入到数据库中。 2.1 用户表 # 用户表相对来说比较简单,要考虑的就是原有的 userid 也要作为字段进行保存,方便在导入评论数据时能找到对应的用户,在评论数据也导入完成后即可将该字段删除,以后新添加的注册用户用不到这个字段了。用户表的设计: 字段 类型 说明 id int 自增,主键 wid int 用户原有的 userid nickname varchar(50) 昵称 avatar varchar(100) 头像 status int 状态 设计好用户表后,将原数据中所有的用户都单独拿出来,然后使用 userid 作为 key 存储到一个数组中,这样也能起到一个去重的效果。把拿到的所有的用户数据存储到用户表 2.2 评论表 # 在设计评论表,主要考虑如下的因素: 评论必须依托于文章和用户才能存在,因此评论的外键是文章标识和 userid,留言板是一个文章内容为空的评论形式; 我想以后新的评论能使用自增 id,而不是跟随原有评论的 cid 来产生新的评论 id,因此这次评论表的主键是 id,原有的评论 id 只作为其中的一个字段 wid 来构造楼中楼的关系,这些旧评论插入到数据表时都会有新的评论 id; 楼中楼的评论是处在某个评论下的,同时,楼中楼里还有相互之前的互动回复。因此这个评论的 pid(parentid)表示当前评论处于哪个评论之下,同时 replyid 表示是回复的哪个评论;若直接回复的父级评论,则 pid 与 replyid 相同,都是父级评论的 id,若回复的不是父级评论,则 pid 为父级评论的 id,replyid 为回复评论的 id;pid 或 replyid 为 0 时,则表示直接对文章发表评论。 因此我们的评论表是这样设计的: 字段 类型 说明 id int 自增,主键 wid int 评论原有的主键 cid uid int 用户 id replyid int 该评论回复的评论 id,没有则为 0 pid int 该评论所在的父级 id,没有则为 0 aid varchar(100) 文章的标识 content varchar(300) 评论内容 createtime int 评论时间的时间戳 表中的 aid(文章的标识)可以是文章的 url,文章的 id 或者其他任何能够唯一识别该文章的东东都可以。这里我们使用的是文章的 uri 来作为唯一标识,比如上面数据中的文章,我们使用/node/2017/02/20/node-express-forum.html来标识文章。其他文章同理。将这些评论写入表时,我们还要注意的是,原数据中,每个评论都对应着一个用户,在我设计的系统里,用户与评论分来了,只使用 uid 来进行关联。新的用户与新的评论都是使用自有的自增主键,因此在原有评论进行入库时,需要将原来的 userid 转换为新用户表中的主键 id,新旧数据进行统一。文章表不做解释。 3. 具体实现 # 前端部分主要是负责展示每个文章的评论,同时让登录用户可以添加评论。 3.1 展示评论 # 我们已经对每个评论都添加了文章标识,前端只要根据 aid 就能拿到当前文章所有的评论。不过我们的评论是要楼中楼的方式展示的,不能一股脑的把数据平铺到页面中。我们在 2.2 中也说了,pid 为 0 的评论都是直接对文章进行评论的,这些评论应该是作为一级评论展示的;pid 为其他数据的,必然是属于某个评论之下,应当作为楼中楼展示。同时,无论一级评论,还是楼中楼的评论,都有可能产生分页的情况,因此这里也要做好分页处理。那么最终,我们前端拿到的结构应该大致是这样的:{ "code": 0, "data": [ { // 一级评论 "id": 1, "content": "蚊子的博客棒棒的", "createtime": "2017年08月08日00:26", "nickname": "匿名者", "reply": { // 楼中楼 "data": [ { "id": 1, "content": "谢谢,一起学习", "createtime": "2017年08月08日00:36", "nickname": "蚊子" } ], "page": { "cur_page": 1, "all_page": 1 } } } ], "page": { "cur_page": 1, "all_page": 1 } } 前端拿到接口返回的数据后,就可以渲染页面了。在头像的处理上,也考虑到了 https 的环境,因此返回的头像链接都是//开头的形式。 3.2 参与评论 # 用户对文章或者某个评论产生了共鸣,需要留言讨论一番,我们就需要用户能够把自己的评论也添加进去。评论的类型,细分的话,可以分为 3 类: 直接对文章发表评论,pid 与 replyid 为空; 对一级评论进行回复,pid 与 replyid 均为一级评论的 id; 对楼中楼进行回复,pid 为一级评论的 id,replyid 为你回复的评论的 id 我这里前端的实现参考了 oschina(开源中国)的评论方式。直接对文章评论,是直接在顶部的评论窗口进行输入;对其他评论进行回复时,采用弹窗的方式来进行回复。弹窗回复的好处就是,页面不用滚动,用户对某个评论的感知也能停留在这个位置;同时也不用增加各种不必要的小输入框来让用户输入评论。 3.3 登录 # 在登录问题上,我也是纠结了不少的时间,究竟是使用自己的登录系统呢,还是使用第三方登录呢,或者是用户不用注册登录,只要输入邮箱和昵称就能进行评论呢?使用自己的评论系统,那么就需要开发一套注册和登录流程,开发麻烦,而且对于想要回复一句话的用户来说,可能就直接放弃注册了;若只要输入邮箱和昵称就能评论,我考虑到可能会引起用户的无限评论,无法控制。因此,最后还是考虑接入第三方的登录,这里选择了使用微博作为第三方登录的入口,后续会考虑加入 github 的帐号登录。关于如何接入微博的第三方登录,我们下篇文章再讲,文档齐全,对不熟悉的开发者来说,刚开始可能有点懵逼,不过应该问题不大。 3.4 添加邮箱功能 # 用户在第三方登录成功后,在名字旁边有个小的 input 输入框,可以让用户输入邮箱来接收回复提醒,这个输入完全是自愿的,不输入邮箱也依然可以评论。也是考虑到本站是个小站,访问量极低,用户可能一时兴起评论了两句,事后又想起这个网站来,又不知道怎么找了。因此就想着添加一个邮件提醒功能,不让大神的评论石沉大海。 3.5 特别注意 # 在刚开始实现完成评论功能的时候,用户只要进到这个页面,评论就会加载。但是有个问题就是,用户不一定会把你的文章看到底部,不一定就看你的评论。因此后来文章就改成了按需加载,只有用户滚动到底部,有想要看评论的意向时采取加载评论。最终展示的效果就是这样: 4. 总结 # 作为一名前端开发,用仅有的后端知识开发一套博客的评论系统,显得是非常的简陋,整个框架的设计感觉也是很糙。同时缓存系统用的不熟练,不能做到评论信息的立即更新。这个系统依然还有很多改进的地方。欢迎大家对蚊子多多提意见和建议。在写这篇文章的时候,想着是以后要改版的时候,可以做成评论同步加载的方式进行。生成后的文章,更新频率极低,甚至不太变动,那么缓存的就是评论的内容,每当有新的评论时,就删除当前文章的缓存,重新加载新的数据,然后再缓存上新的数据,这样在评论数据更新比较低的时候,可以缓存的时间更长,同时也有利于搜索引起对评论内容的抓取。 -
金秋9月的思考 今天是 2017 年 9 月 1 号,夏天就这么过去了,晚上睡觉的时候也凉了很多,不用再开空调了。每次写点东西时,都是感慨时间过的太快,2017 年已经过去 2/3 了,你到现在做了什么吗,有什么收获吗?看看自己之前写的文章其实也能看到自己的状态,在 3,4,5,6 这四个月里,一共才发了 7 篇文章,而且整个 5 月里一篇文章也没有。要说工作忙也是一方面原因,没有空出时间来总结和学习;再一个就是自己确实变懒了,晚上回家想着能多休息会儿,多玩会儿。总说现在的年轻人焦虑,毕竟生活、工作、居住这么艰难,怎么能不焦虑呢?多学习学习,多赚点钱,让媳妇和孩子能有个自己的房子,让父母亲人在还能行动之前带他们出去走走,让他们享享晚年的幸福。前几天,爷爷突然就去世了,真是那句话:“明天和意外,你永远不知道哪个先来”,辛苦了一辈子,就这么走了。只希望自己能成长的快一些,让家人老的慢一些!这篇文章的格调好像有点沉重,不过前途依然是光明的。很多人觉得上帝没有眷顾到我们,其实上帝已经替我们挡了无数的伤害。“哪有什么岁月静好,不过是有人替你负重前行”!加油!
-
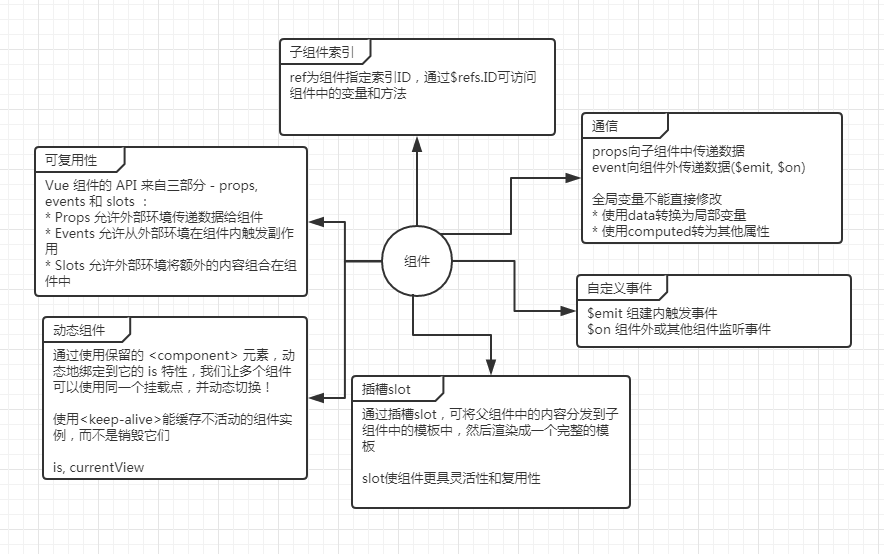
Vue组件实现tips的总结 官网上已经有的内容,我就不再赘述了,直接在官网上查看即可,这里蚊子想换个角度来讲解下vue的组件。组件,顾名思义,就是把一个相对独立,而且会多次使用的功能抽象出来,成为一个组件!如果我们要把某个功能抽象为一个组件时,要做到这个组件对其他人来说是个黑盒子,他们不用关心里面是怎么实现的,只需要根据约定的接口调用即可!我用一张图稍微总结了下Vue中组件的构成:可以看到组件中包含的东西还是蛮多的,而且,还有很多的点没有列出来,这里面的每一个知识点能都展开讲很多。不过我们这里不讲原理,只讲使用。我们以一个tips弹窗为例,来综合运用下组件的知识点。tips弹窗,几乎所有的框架或者类库,都会有弹窗这个组件,因为弹窗这个功能平时非常普遍,而且模块解耦度高!我们先来看下demo: 【 demo 】。 1. 接口约定 # 我们这里实现的弹窗,能用到的知识点有:props, event, slot, ref等。这里我们也能看到各个知识点是怎么运用的。/** * modal 模态接口参数 * @param {string} modal.title 模态框标题 * @param {string} modal.text 模态框内容 * @param {boolean} modal.showbtn 是否显示按钮 * @param {string} modal.btnText 按钮文字 */ Vue.component('tips', { props : ['tipsOptions'], template : '#tips', data(){ return{ show : false } }, computed:{ tips : { get() { let tips = this.tipsOptions || {}; tips = { title: tips.title || '提示', text: tips.text || '', showbtn : tips.showbtn || true, btnText : tips.btnText || '确定' }; // console.log(tips); return tips; } } } }) 2. modal组件的实现 # tips组件相对来说实现的比较简单,仅用作提示用户的简单弹层。模板: x {{tips.title}} {{tips.text}} {{tips.btnText}} 模板中将结构分成了三部分,标题、内容和操作区域。这里既可以使用props传递字符串,也可以使用slot进行定制。tips样式:.tips { position: fixed; left: 10px; bottom: 10px; z-index: 1001; -webkit-overflow-scrolling: touch; max-width: 690px; width: 260px; padding: 10px; background: #fff; box-shadow: 0 0 10px #888; border-radius: 4px; } .tips-close{ position: absolute; top: 0; right: 0; width: 20px; height: 20px; line-height: 20px; text-align: center; } .tips-header{ text-align: center; font-size: 25px; } 组件内的方法:methods:{ closeTips(){ this.show = false; }, yes : function(){ this.show = false; this.$emit('yes', {name:'wenzi', age:36}); // 触发yes事件 }, showTips(){ var self = this; self.show = true; setTimeout(function(){ // self.show = false; }, 2000) } } 3. 调用tips组件 # 首先我们开始渲染组件: 显示 提示标题 hello world wenzi 点击显示按钮后展示tips:var app = new Vue({ el : '.app', data : { tipsOptions : { title : 'tip' } } methods:{ // 监听从组件内传递出来的事件 yes(args){ // console.log( args ); alert( JSON.stringify(args) ); }, // 显示tips showtips(){ // console.log( this.$refs ); this.$refs.dialog.showTips(); } } }) 4. 总结 # 在这个简单的tips组件里,我们实现了用props传递参数,用$emit向外传递参数,用slot插槽来定制内容。需要注意的是:组件props是单向绑定,即父组件的属性发生变化时,子组件能接收到相应的数据变化,但是反过来就会出错。即不能在子组件中修改props传过来的数据,来达到修改父组件属性的目的。这是为了防止子组件无意修改了父组件的状态。另外,每次父组件更新时,子组件的所有 prop 都会更新为最新值。这意味着你不应该在子组件内部改变 prop。如果你这么做了,Vue 会在控制台给出警告。如果真的需要在子组件里进行修改,可以用这两种方法应对:定义一个局部变量,并用 prop 的值初始化它:props: ['initialCounter'], data: function () { return { counter: this.initialCounter } } 定义一个计算属性,处理 prop 的值并返回。props: ['size'], computed: { normalizedSize: function () { return this.size.trim().toLowerCase() } } 当然,这只是单页面中组件的实现,更复杂的组件后续我们也会实现。
-
浅谈javascript设计模式之发布订阅者模式 发布订阅者模式又称为观察者模式,有的书本中也对这两个模式进行了更加细致的区分!这里我们只研究发布订阅者模式。 1. 什么是发布订阅者模式 # 发布订阅者模式,我们可以通俗地用微信公众号来比喻: 只有该公众号的订阅者才能收到推送 公众号只负责推送信息,不关心是谁订阅了我,只要有信息推送,那么就推送给所有的订阅者 订阅者无需时不时的查看公众号是否有信息推送,只要公众号推送信息后,该订阅者就会收到通知 订阅者可随时取消对该公众号的订阅 从这个比喻来看,发布订阅者模式是为了发布者和订阅者之间避免产生依赖关系,发布订阅者之间的订阅关系由一个中介列表来维护。发布者只需做好发布功能,至于订阅者是谁,订阅者做了什么事情,发布者是无需关心的。 2. 模式的使用场景 # 发布订阅者模式中的事件驱动和解耦性,让我们非常方便地使用在一些场景中,比如ajax数据返回后的展示,厂家通知所有订阅用户新品已发布,异步登录,等等。发布订阅者模式,可以让我们不再涉及更多的回调处理,而且可以使模块的颗粒度更小。比如有个ajax的数据展示,其中一个订阅者A可以只负责数据的表格展示,另一个订阅者B只负责数据总量的计算。当有需求要把数据总量的计算修改为当前页的数据总量和整体的数据总量计算,那么订阅者A是不用任何变动的! 2. 如何实现一个发布订阅者模式 # 在发布订阅者模式中,我们需要的功能有: 订阅,发布,取消订阅,还有一个列表来维护它们之间的订阅关系。var pubsub = {}; //订阅关系列表 ;(function(q){ var topics = [], subUid = -1; // 添加订阅者 q.subscribe = function(topic, func){ var token = (++subUid).toString(); if( !topics[topic] ){ topics[topic] = []; } topics[topic].push({ token : token, func : func }); return token; } // 触发 q.publish = function(topic, args){ var ss = topics[topic], len = ss ? ss.length: 0; // 取出订阅该主题所有的订阅者 while(len--){ var func = ss[len].func; func(topic, args); } } // 取消订阅 q.unsubscribe = function(token){ for(var key in topics){ if( topics[key] ){ var item; for(var i=0, len=topics[key].length; i
-
作为开发者,如何树立个人品牌? 作为一名 PHP 开发者,自从我开始在网站上“露脸”以来,我的博客和社交媒体帐户的访问量就有所增加。虽然只是轻微的增长,但对我来说依然很激动,使我更加充满激情。对于个人品牌,这是我过去所忽视的,直至近期才开始重视它。我很满意目前的工作并且暂不会考虑换工作,但我低估了在线上积极展示自我的重要性。就在上周,我深刻明白了自己以往的单纯。让我醒悟的起由,源于我所在的公司最近在招聘多个职位,并且收到了大量的申请。令我惊讶的是,我的老板通过谷歌搜索申请人的名字从而了解他们在线上的表现。我的老板正在使用这个方式来寻找积极的贡献者信息。他并没有在 Facebook 上试图找出候选人在星期五晚上做了什么。他更感兴趣的是:申请人是否有博客?有没有其他特殊爱好?工作以外参与的热门项目?这让我联想到自己的“个人品牌”,我决定开始恶补,怒刷线上存在感。关于个人品牌的建设,笔者在此做了一些自己的尝试和思考,希望对大家有所帮助。 完善博客 # 如果你还没有博客,请尝试购买一个{你的姓名}.com 的域名。如果无法买到 .com,那么 .co .uk或其他本地 TLD 亦可。如果做商业网站,那么具有特殊意义的域名是非常好的。但是,如果你正在建立个人品牌,那么域名最好和自己姓名相关。这不是简单的为了让你的网站访问量达到1000人。这是为了树立个人品牌。最终,一个潜在的雇主或者客户可能会用 Google 搜索到你的名字。搭建个人博客并不昂贵。你可以使用免费主题的 Wordpress 快速开启个人博客之旅。此外,还有一些类似 Jekyll 的其他平台可以使用。Wordpress 使用非常简单,不需要依赖任何其他的设置。博客的界面不需要太花哨,它是一个线上展示自我的空间,别人可以在网上找到你,通过博客内容加深对你的了解,如果需要的话可以通过博客和你取得联系。最好不要对每一篇博文都精益求精并且花费非常多的时间来修修补补。自我学习和陪伴家人同样是生活中的重要部分。持续地定期发布博文即可。不要担心自己的文章技术深度不够。因为即使你是一名编程初学者,那么一定有比你更菜的初学者存在,哪怕你的经验只比他们多一个月、一周、哪怕是一天,总有人能够从你的文章中获益。写一些技术之外的文章也是可以的,通过分享自己的兴趣爱好和特长是展示自我除了代码之外独特个性的很好方式。只是文章内容尽量不要有争议。 使用社交网络,如 Twitter、微博 # 我本人并不热衷社交网络。但是考虑到我的个人品牌建设,于是我决定注册一个Twitter 账号。Twitter 是接触圈内“大牛”的重要途径。比方说,我最近发布了一则推文表达我对学习Slim 框架的兴趣。令我惊讶的是,第一个答复者竟然是该框架的其中一个核心贡献者。试想,谁的建议和指导会比他更好呢?身处社区之中,你可以及时获取前沿技术动态和行业新闻。通过 Twitter 你可以在参加会议之前和与会者提前打招呼并熟悉对方。需要记住的是,你的推文全世界的人都可以看到。所以,请尽量发布有帮助、友好、有价值的推文。一日三餐、生活琐事这类毫无意义的推文是不受欢迎的。在中国,微博不乏为一种有效的途径。社交媒体是建立个人品牌的绝佳机会,使用网络来分享你的热情和知识吧。 所有平台同步更新 # 提到一个品牌,首先印入脑海的也许是一个特定的 logo、slogan 或者图片。同样,这也适用于个人品牌。确保你在所有不同平台或者网站上都使用相同的个人资料和头像。我就犯了一个错误,我在媒体网站和 Twitter 上使用了不同的头像。人们第一眼看到这两个不同的头像就无法快速知道这是同一个人。你的目的是让更多的人认识你并且构建你的个人品牌,因此你最好不要在不同的平台使用五花八门的头像和用户名。切记,使用一份相同的个人信息。 以开发者自居 # 哪怕你是一个处在学习阶段的软件开发新人,也不要屏蔽工作机会。你的博客和社交媒体帐户可以展示自我,可以表明你是一个“有抱负的开发人员”或者“参与了专业培训的开发人员”。招聘经理会对没有太多实际经验但是充满热情的开发者感兴趣吗?当然,工作热情是招聘的重要条件。即使你已经有了一份其他行业的稳定工作,只是在晚上自学编程技能,你仍然可以称作一个“开发人员”(他们在白天做自己的工作,晚上编写代码)。评估开发水平的方式有很多。但是,第一印象是代码量,所以要尽量多动手编码。作为一名开发人员,并且正在寻找开发工作,那么就要努力确保自己是一名合格的开发者。 去除“初级”标签 # 我突然意识到我在博客和社交媒体上把自己称为“初级”开发者。实际上我已经30岁了,实力上来讲完全不是初级水平。老实说,仅仅用初级一词来评判开发者水平是没有意义的,这取决于个人看法。一个初级开发人员可能是一个很少甚至没有工作经验的人。但是,如果那个人在过去十年里一直在空闲时间编写代码呢,他还是初级水平吗? 又或者有的人可能有几年的商业开发经验,但是真实水平却不高呢?现实来讲,不要称自己为初级开发者。这对你没有任何好处,反而会限制你的就业潜力。有公司或者招聘者在招聘广告指明中级开发者实际上会考虑“初级”吗?你不想让他们说:“稍等一会儿,你符合我们的所有招聘要求,有几年的工作经验。但是抱歉,我们不是在找一个初级开发者。” 突出你最擅长的领域 # 在我的博客和社交媒体上,我称自己为“Web 开发者”。的确,我主要使用一系列 Web 技术来开发 Web 应用程序。确切地说,我是一名 PHP 开发人员。我对 JavaScript 不是很精通,所以我不会很轻松找到一个 JavaScript 开发人员的工作。另外,我的 Ruby on Rails 也比较菜,老实说我只花了大约一个小时来学习它的教程。所以我决定把自己的个人品牌打造为 PHP 开发者。这样能够更加准确地展示我的技能和专长。为了获得更好的机会,你需要突出自己最擅长的领域。 整理你的 Github # 前段时间一个同事浏览了我的 Github,他对我业余时间在 Github 的活跃度感到震惊。后来他发现我的项目几乎都是完成一半、杂乱、“WIP”(正在进行中),于是对我产生了不好的印象。的确,太多这样的项目无法展示自己是一个频繁提交、按时交付并且能够有始有终完成一个项目的开发者。在 GitHub 上保持活跃度是好的,但是如果你永远不会完成这些项目,那么我建议删掉它们。招聘人员希望看到的是已经完成以及你最引以为傲的项目,而不是你认为有意义但是没有投入时间而一直搁浅的项目。 展示你的激情 # 使用博客、社交媒体、GitHub 和在线平台强调你对开发工作的热爱。尽可能地展现自己引以为傲的项目和工作激情。在这一点上,我引用两位程序员在 stack-overflow 上的回答:热情 VS 经验。 对开发工作充满热情的开发者值得招聘,哪怕他没有相关经验。一个充满激情的程序员会快速学习,专心投入他们的工作,并且非常热爱开发工作。我和这两种类型的多个程序员合作过,相比有经验的,我永远会优先聘请有激情的程序员。 不关心工作进度的人同样不会关心他们的工作质量。 如果你有资源培训新招的开发者,那么毋庸置疑,你应当 招聘那些充满激情的程序员。 转载自: https://mp.weixin.qq.com/s/yYfzGExdG6ZQyrvfv273tg