搜索到
1237
篇与
的结果
-
 如何解决移动端的安全区域为0的问题 从 iPhone X 开始出现了刘海和底部的黑条的区域,而 Android 系统通常也会模仿 iPhone 的一些设计,然后就是现在越来越多地新机型有了安全区域的概念。若完全不考虑这些,可能就会出现类似这样的情况:因此我们需要对这些区域做些特殊地处理。 1. 适配 iOS 中的安全区域 # 在大部分机型,尤其是 iOS 设备中,适配安全区域还是比较简单的,主要是 3 个步骤。 1.1 设置网页在可视窗口的布局方式 # 新增 viweport-fit 属性,使得页面内容完全覆盖整个窗口: 只有设置了 viewport-fit=cover,才能使用 env()。 1.2 限定安全区域 # iOS11 新增特性,Webkit 的一个 CSS 函数,用于设定安全区域与边界的距离,有四个预定义的变量: safe-area-inset-left:安全区域距离左边边界的距离 safe-area-inset-right:安全区域距离右边边界的距离 safe-area-inset-top:安全区域距离顶部边界的距离 safe-area-inset-bottom:安全区域距离底部边界的距离 这里我们只需要关注safe-area-inset-bottom这个变量,因为它对应的就是小黑条的高度。注意:当 viewport-fit=contain 时 env() 是不起作用的,必须要配合 viewport-fit=cover 使用。对于不支持 env() 的浏览器,浏览器将会忽略它。 The env() function shipped in iOS 11 with the name constant(). Beginning with Safari Technology Preview 41 and the iOS 11.2 beta, constant() has been removed and replaced with env(). You can use the CSS fallback mechanism to support both versions, if necessary, but should prefer env() going forward. 这就意味着,之前使用的 constant() 在 iOS11.2 之后就不能使用的,但我们还是需要做向后兼容,像这样:body { padding-bottom: constant(safe-area-inset-bottom); /* 兼容 iOS < 11.2 */ padding-bottom: env(safe-area-inset-bottom); /* 兼容 iOS >= 11.2 */ } 注意:env() 跟 constant() 需要同时存在,而且顺序不能换。在竖屏的情况下,若要限定顶部的刘海区域,则要使用safe-area-inset-top;若要限定底部的区域,则要使用safe-area-inset-bottom。若需要进行计算,则可以使用calc()函数:body { padding-bottom: calc(12px + constant(safe-area-inset-bottom)); padding-bottom: calc(12px + env(safe-area-inset-bottom)); } 2. 部分奇特的 Android 手机 # 很多 Android 手机也会按照 iOS 的标准来实现安全区域,因此上面的属性在大部分 Android 手机上也能正常使用。但是,我们在测试的过程中发现,有几个奇特的手机,会出现下图的状况:通过 Chrome 查看样式,发现他会识别 safe-area-inset-top 等预定义变量,但又将其解析为 0。这就导致即使我们设置了兜底的数据,也无法使用。例如我们在不支持安全区域属性时,使用兜底的 padding-top: 25PX 样式(大写的 PX 是为了不被插件转义成 vw 或 rem),但上述的 Android 设备中,兜底样式也不会生效:body { /* prettier-ignore */ padding-top: 25PX; padding-top: constant(safe-area-inset-top); padding-top: env(safe-area-inset-top); } 那么如何解决这个问题呢? 3. 解决方案 # 这里我们就要借助 js 来实现了。首先我们向页面中插入一个看不见的 div,将 div 的高度设置为安全距离的高度,然后再通过 js 获取其高度,若高度为 0,则说明没有生效。let status = 0; // 0:还没数据,-1:不支持,1:支持 /** * 判断当前设置是否支持constant(safe-area-inset-top)或env(safe-area-inset-top); * 部分Android设备,可以认识safa-area-inset-top,但会将其识别为0 * @returns {boolean} 当前设备是否支持安全距离 */ const supportSafeArea = (): boolean => { if (status !== 0) { // 缓存数据,只向 body 插入一次 dom 即可 return status === 1; } const div = document.createElement('div'); const id = 'test-check-safe-area'; const styles = [ 'position: fixed', 'z-index: -1', 'height: constant(safe-area-inset-top)', 'height: env(safe-area-inset-top)', ]; div.style.cssText = styles.join(';'); div.id = id; document.body.appendChild(div); const areaDiv = document.getElementById(id); if (areaDiv) { status = areaDiv.offsetHeight > 0 ? 1 : -1; // 该 div 的高度是否为 0 areaDiv.parentNode?.removeChild(areaDiv); } return status === 1; }; 那么在已经设置了安全区域属性的地方,都需要额外执行下 supportSafeArea()方法:const SignTaskDetail = () => { const [safaArea, setSafeArea] = useState(true); // 当前页面是否支持 safe-area-inset-top useEffect(() => { setSafeArea(supportSafeArea()); }, []); return ( ); }; 4. 总结 # 设备兼容性一直我们前端在解决的问题,无论是在 PC 端还是在移动端,浏览器的多样性和编程语言的发展,必然需要解决这些问题。
如何解决移动端的安全区域为0的问题 从 iPhone X 开始出现了刘海和底部的黑条的区域,而 Android 系统通常也会模仿 iPhone 的一些设计,然后就是现在越来越多地新机型有了安全区域的概念。若完全不考虑这些,可能就会出现类似这样的情况:因此我们需要对这些区域做些特殊地处理。 1. 适配 iOS 中的安全区域 # 在大部分机型,尤其是 iOS 设备中,适配安全区域还是比较简单的,主要是 3 个步骤。 1.1 设置网页在可视窗口的布局方式 # 新增 viweport-fit 属性,使得页面内容完全覆盖整个窗口: 只有设置了 viewport-fit=cover,才能使用 env()。 1.2 限定安全区域 # iOS11 新增特性,Webkit 的一个 CSS 函数,用于设定安全区域与边界的距离,有四个预定义的变量: safe-area-inset-left:安全区域距离左边边界的距离 safe-area-inset-right:安全区域距离右边边界的距离 safe-area-inset-top:安全区域距离顶部边界的距离 safe-area-inset-bottom:安全区域距离底部边界的距离 这里我们只需要关注safe-area-inset-bottom这个变量,因为它对应的就是小黑条的高度。注意:当 viewport-fit=contain 时 env() 是不起作用的,必须要配合 viewport-fit=cover 使用。对于不支持 env() 的浏览器,浏览器将会忽略它。 The env() function shipped in iOS 11 with the name constant(). Beginning with Safari Technology Preview 41 and the iOS 11.2 beta, constant() has been removed and replaced with env(). You can use the CSS fallback mechanism to support both versions, if necessary, but should prefer env() going forward. 这就意味着,之前使用的 constant() 在 iOS11.2 之后就不能使用的,但我们还是需要做向后兼容,像这样:body { padding-bottom: constant(safe-area-inset-bottom); /* 兼容 iOS < 11.2 */ padding-bottom: env(safe-area-inset-bottom); /* 兼容 iOS >= 11.2 */ } 注意:env() 跟 constant() 需要同时存在,而且顺序不能换。在竖屏的情况下,若要限定顶部的刘海区域,则要使用safe-area-inset-top;若要限定底部的区域,则要使用safe-area-inset-bottom。若需要进行计算,则可以使用calc()函数:body { padding-bottom: calc(12px + constant(safe-area-inset-bottom)); padding-bottom: calc(12px + env(safe-area-inset-bottom)); } 2. 部分奇特的 Android 手机 # 很多 Android 手机也会按照 iOS 的标准来实现安全区域,因此上面的属性在大部分 Android 手机上也能正常使用。但是,我们在测试的过程中发现,有几个奇特的手机,会出现下图的状况:通过 Chrome 查看样式,发现他会识别 safe-area-inset-top 等预定义变量,但又将其解析为 0。这就导致即使我们设置了兜底的数据,也无法使用。例如我们在不支持安全区域属性时,使用兜底的 padding-top: 25PX 样式(大写的 PX 是为了不被插件转义成 vw 或 rem),但上述的 Android 设备中,兜底样式也不会生效:body { /* prettier-ignore */ padding-top: 25PX; padding-top: constant(safe-area-inset-top); padding-top: env(safe-area-inset-top); } 那么如何解决这个问题呢? 3. 解决方案 # 这里我们就要借助 js 来实现了。首先我们向页面中插入一个看不见的 div,将 div 的高度设置为安全距离的高度,然后再通过 js 获取其高度,若高度为 0,则说明没有生效。let status = 0; // 0:还没数据,-1:不支持,1:支持 /** * 判断当前设置是否支持constant(safe-area-inset-top)或env(safe-area-inset-top); * 部分Android设备,可以认识safa-area-inset-top,但会将其识别为0 * @returns {boolean} 当前设备是否支持安全距离 */ const supportSafeArea = (): boolean => { if (status !== 0) { // 缓存数据,只向 body 插入一次 dom 即可 return status === 1; } const div = document.createElement('div'); const id = 'test-check-safe-area'; const styles = [ 'position: fixed', 'z-index: -1', 'height: constant(safe-area-inset-top)', 'height: env(safe-area-inset-top)', ]; div.style.cssText = styles.join(';'); div.id = id; document.body.appendChild(div); const areaDiv = document.getElementById(id); if (areaDiv) { status = areaDiv.offsetHeight > 0 ? 1 : -1; // 该 div 的高度是否为 0 areaDiv.parentNode?.removeChild(areaDiv); } return status === 1; }; 那么在已经设置了安全区域属性的地方,都需要额外执行下 supportSafeArea()方法:const SignTaskDetail = () => { const [safaArea, setSafeArea] = useState(true); // 当前页面是否支持 safe-area-inset-top useEffect(() => { setSafeArea(supportSafeArea()); }, []); return ( ); }; 4. 总结 # 设备兼容性一直我们前端在解决的问题,无论是在 PC 端还是在移动端,浏览器的多样性和编程语言的发展,必然需要解决这些问题。 -
基于 IntersectionObserver 实现一个组件的曝光监控 我们在产品推广过程中,经常需要判断用户是否对某个模块感兴趣。那么就需要获取该模块的曝光量和用户对该模块的点击量,若点击量/曝光量越高,说明该模块越有吸引力。那么如何知道模块对用户是否曝光了呢?之前我们是监听页面的滚动事件,然后通过getBoundingClientRect()现在我们直接使用IntersectionObserver就行了,使用起来简单方便,而且性能上也比监听滚动事件要好很多。 1. IntersectionObserver # 我们先来简单了解下这个 api 的使用方法。IntersectionObserver 有两个参数,new IntersectionObserver(callback, options),callback 是当触发可见性时执行的回调,options 是相关的配置。// 初始化一个对象 const io = new IntersectionObserver( (entries) => { // entries是一个数组 console.log(entries); }, { threshold: [0, 0.5, 1], // 触发回调的节点,0表示元素刚完全不可见,1表示元素刚完全可见,0.5表示元素可见了一半等 }, ); // 监听dom对象,可以同时监听多个dom元素 io.observe(document.querySelector('.dom1')); io.observe(document.querySelector('.dom2')); // 取消监听dom元素 io.unobserve(document.querySelector('.dom2')); // 关闭观察器 io.disconnect(); 在 callback 中的 entries 参数是一个IntersectionObserverEntry类型的数组。主要有 6 个元素: { time: 3893.92, rootBounds: ClientRect { bottom: 920, height: 1024, left: 0, right: 1024, top: 0, width: 920 }, boundingClientRect: ClientRect { // ... }, intersectionRect: ClientRect { // ... }, intersectionRatio: 0.54, target: element } 各个属性的含义:{ time: 触发该行为的时间戳(从打开该页面开始计时的时间戳),单位毫秒 rootBounds: 视窗的尺寸, boundingClientRect: 被监听元素的尺寸, intersectionRect: 被监听元素与视窗交叉区域的尺寸, intersectionRatio: 触发该行为的比例, target: 被监听的dom元素 } 我们利用页面可见性的特点,可以做很多事情,比如组件懒加载、无限滚动、监控组件曝光等。 2. 监控组件的曝光 # 我们利用IntersectionObserver这个 api,可以很好地实现组件曝光量的统计。实现的方式主要有两种: 函数的方式; 高阶组件的方式; 传入的参数:interface ComExposeProps { readonly always?: boolean; // 是否一直有效 // 曝光时的回调,若不存在always,则只执行一次 onExpose?: (dom: HTMLElement) => void; // 曝光后又隐藏的回调,若不存在always,则只执行一次 onHide?: (dom: HTMLElement) => void; observerOptions?: IntersectionObserverInit; // IntersectionObserver相关的配置 } 我们约定整体的曝光量大于等于 0.5,即为有效曝光。同时,我们这里暂不考虑该 api 的兼容性,若需要兼容的话,可以安装对应的 polyfill 版。 2.1 函数的实现方式 # 用函数的方式来实现时,需要业务侧传入真实的 dom 元素,我们才能监听。// 一个函数只监听一个dom元素 // 当需要监听多个元素,可以循环调用exposeListener const exposeListener = (target: HTMLElement, options?: ComExposeProps) => { // IntersectionObserver相关的配置 const observerOptions = options?.observerOptions || { threshold: [0, 0.5, 1], }; const intersectionCallback = (entries: IntersectionObserverEntry[]) => { const [entry] = entries; if (entry.isIntersecting) { if (entry.intersectionRatio >= observerOptions.threshold[1]) { if (target.expose !== 'expose') { options?.onExpose?.(target); } target.expose = 'expose'; if (!options?.always && typeof options?.onHide !== 'function') { // 当always属性为加,且没有onHide方式时 // 则在执行一次曝光后,移动监听 io.unobserve(target); } } } else if (typeof options?.onHide === 'function' && target.expose === 'expose') { options.onHide(target); target.expose = undefined; if (!options?.always) { io.unobserve(target); } } }; const io = new IntersectionObserver(intersectionCallback, observerOptions); io.observe(target); }; 调用起来也非常方便:exposeListener(document.querySelector('.dom1'), { always: true, // 监听的回调永远有效 onExpose() { console.log('dom1 expose', Date.now()); }, onHide() { console.log('dom1 hide', Date.now()); }, }); // 没有always时,所有的回调都只执行一次 exposeListener(document.querySelector('.dom2'), { // always: true, onExpose() { console.log('dom2 expose', Date.now()); }, onHide() { console.log('dom2 hide', Date.now()); }, }); // 重新设置IntersectionObserver的配置 exposeListener(document.querySelector('.dom3'), { observerOptions: { threshold: [0, 0.2, 1], }, onExpose() { console.log('dom1 expose', Date.now()); }, }); 那么组件的曝光数据,就可以在onExpose()的回调方式里进行上报。不过我们可以看到,这里面有很多标记,需要我们处理,单纯的一个函数不太方便处理;而且也没对外暴露出取消监听的 api,导致我们想在卸载组件前也不方便取消监听。因此我们可以用一个 class 类来实现。 2.2 类的实现方式 # 类的实现方式,我们可以把很多标记放在属性里。核心部分跟上面的差不多。class ComExpose { target = null; options = null; io = null; exposed = false; constructor(dom, options) { this.target = dom; this.options = options; this.observe(); } observe(options) { this.unobserve(); const config = { ...this.options, ...options }; // IntersectionObserver相关的配置 const observerOptions = config?.observerOptions || { threshold: [0, 0.5, 1], }; const intersectionCallback = (entries) => { const [entry] = entries; if (entry.isIntersecting) { if (entry.intersectionRatio >= observerOptions.threshold[1]) { if (!config?.always && typeof config?.onHide !== 'function') { io.unobserve(this.target); } if (!this.exposed) { config?.onExpose?.(this.target); } this.exposed = true; } } else if (typeof config?.onHide === 'function' && this.exposed) { config.onHide(this.target); this.exposed = false; if (!config?.always) { io.unobserve(this.target); } } }; const io = new IntersectionObserver(intersectionCallback, observerOptions); io.observe(this.target); this.io = io; } unobserve() { this.io?.unobserve(this.target); } } 调用的方式:// 初始化时自动添加监听 const instance = new ComExpose(document.querySelector('.dom1'), { always: true, onExpose() { console.log('dom1 expose'); }, onHide() { console.log('dom1 hide'); }, }); // 取消监听 instance.unobserve(); 不过这种类的实现方式,在 react 中使用起来也不太方便: 首先要通过useRef()获取到 dom 元素; 组件卸载时,要主动取消对 dom 元素的监听; 2.3 react 中的组件嵌套的实现方式 # 我们可以利用 react 中的useEffect()hook,能很方便地在卸载组件前,取消对 dom 元素的监听。import React, { useEffect, useRef, useState } from 'react'; interface ComExposeProps { children: any; readonly always?: boolean; // 是否一直有效 // 曝光时的回调,若不存在always,则只执行一次 onExpose?: (dom: HTMLElement) => void; // 曝光后又隐藏的回调,若不存在always,则只执行一次 onHide?: (dom: HTMLElement) => void; observerOptions?: IntersectionObserverInit; // IntersectionObserver相关的配置 } /** * 监听元素的曝光 * @param {ComExposeProps} props 要监听的元素和回调 * @returns {JSX.Element} */ const ComExpose = (props: ComExposeProps): JSX.Element => { const ref = useRef(null); const curExpose = useRef(false); useEffect(() => { if (ref.current) { const target = ref.current; const observerOptions = props?.observerOptions || { threshold: [0, 0.5, 1], }; const intersectionCallback = (entries: IntersectionObserverEntry[]) => { const [entry] = entries; if (entry.isIntersecting) { if (entry.intersectionRatio >= observerOptions.threshold[1]) { if (!curExpose.current) { props?.onExpose?.(target); } curExpose.current = true; if (!props?.always && typeof props?.onHide !== 'function') { // 当always属性为加,且没有onHide方式时 // 则在执行一次曝光后,移动监听 io.unobserve(target); } } } else if (typeof props?.onHide === 'function' && curExpose.current) { props.onHide(target); curExpose.current = false; if (!props?.always) { io.unobserve(target); } } }; const io = new IntersectionObserver(intersectionCallback, observerOptions); io.observe(target); return () => io.unobserve(target); // 组件被卸载时,先取消监听 } }, [ref]); // 当组件的个数大于等于2,或组件使用fragment标签包裹时 // 则创建一个新的div用来挂在ref属性 if (React.Children.count(props.children) >= 2 || props.children.type.toString() === 'Symbol(react.fragment)') { return {props.children}; } // 为该组件挂在ref属性 return React.cloneElement(props.children, { ref }); }; export default ComExpose; 调用起来更加方便了,而且还不用手动获取 dom 元素和卸载监听: console.log('expose')} onHide={() => console.log('hide')}> dom1 always Vue 组件实现起来的方式也差不多,不过我 Vue 用的确实比较少,这里就不放 Vue 的实现方式了。 3. 总结 # 现在我们已经基本实现了关于组件的曝光的监听方式,整篇文章的核心全部都在IntersectionObserver上。基于上面的实现方式,我们其实还可以继续扩展,比如在组件即将曝光时踩初始化组件;页面中的倒计时只有在可见时才执行,不可见时则直接停掉等等。IntersectionObserver 还等着我们探索出更多的用法!
-
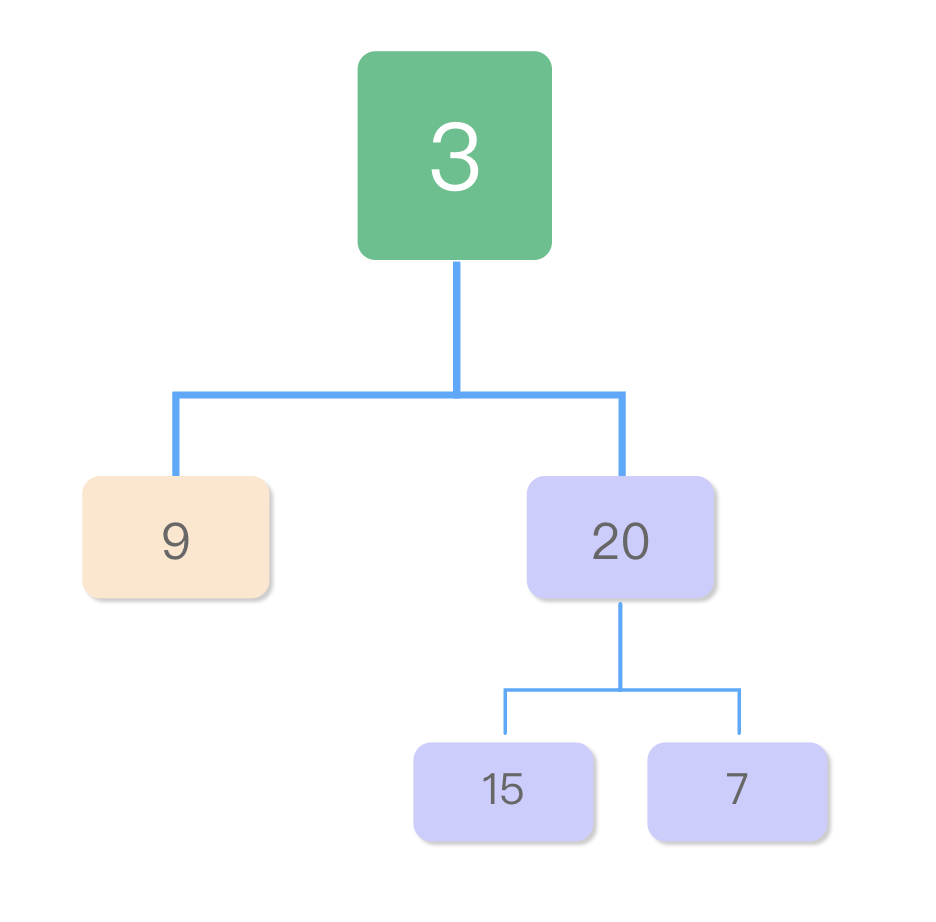
将leetcode中二叉树的数组结构转为真实的树结构 我们在 LeetCode 上锻炼算法时,关于二叉树的题目,网站上给的都直接是一个数组,那么本地测试的时候,就很不方便。官方文档中的解释是这样的:请问 [1, null, 2, 3] 在二叉树测试用例中代表什么。 1. javascript 版本 # 我们首先定义一个 TreeNode 的结构:function TreeNode(val) { this.val = val; this.left = this.right = null; } 我们用循环的方式,将数组转为二叉树结构。const array2binary = (arr) => { if (!arr || !arr.length) { return null; } let index = 0; const queue = []; const len = arr.length; const head = new TreeNode(arr[index]); queue.push(head); while (index < len) { index++; const parent = queue.shift(); if (arr[index] !== null && arr[index] !== undefined) { const node = new TreeNode(arr[index]); parent.left = node; queue.push(node); } index++; if (arr[index] !== null && arr[index] !== undefined) { const node = new TreeNode(arr[index]); parent.right = node; queue.push(node); } } return head; }; 使用:const root = array2binary([3, 9, 20, null, null, 15, 7]); 最终转换成的树形结构: 2.C++ 版本 # 在 C++中的 vector 数据结构里,只能有一种类型,这里我们用INT_MAX来代替 null,需要转换的数组中的 null 也请用 INT_MAX 来代替。我们的转换程序主要是应用在本地,为了方便本地的调试,因此在使用时,尤其要注意数据的范围,若真的用到了 INT_MAX 对应的数据,请把转换程序中代替 null 的INT_MAX更换为其他数字。官方给的二叉树结构为:struct TreeNode { int val; TreeNode *left; TreeNode *right; TreeNode() : val(0), left(nullptr), right(nullptr) {} TreeNode(int x) : val(x), left(nullptr), right(nullptr) {} TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {} }; 我们的转换程序如下:/** * 将leetcode中的数组转为二叉树 * 因C++中的vector只能是同一个类型,这里用INT_MAX来代替null * @param {vector} nums * @return {TreeNode} */ TreeNode *vectorToTree(vector nums){ int i = 1; bool isLeftTree = true; // 是否是左分支,true为左分支,false时是右分支 if (nums.size() == 0) { return nullptr; } queue myQueue; TreeNode *head = new TreeNode(nums[0]); myQueue.push(head); while (i < nums.size()) { TreeNode *topNode = myQueue.front(); // 这里我们与js版稍微有点区别 // 队列中的节点只要用两次,当isLeftTree指向到右分支时,说明可以取出了 if (!isLeftTree) { myQueue.pop(); } // 我们用INT_MAX来标识nullptr if (nums[i] != INT_MAX) { TreeNode *node = new TreeNode(nums[i]); if (isLeftTree) { topNode->left = node; } else { topNode->right = node; } myQueue.push(node); } isLeftTree = !isLeftTree; i++; } return head; } 使用:vector nums = {3, 9, 20, INT_MAX, INT_MAX, 15, 7}; TreeeNode *root = vectorToTree(nums); 3. 测试 # 我们可以在 leetcode 中选择一个题目来测试下,就选最简单的二叉树前序遍历。把题目中给到的数组数据,转为二叉树数据,然后再调试您的程序吧。 4. 题外话 # 刚开始经同事提示,添加了一个递归的方式,如:// 错误代码,请不要直接使用 const array2binary = (arr, index = 0) => { if (!arr || arr[index] === null || index >= arr.length) { return null; } const node = new TreeNode(arr[index]); node.left = array2binary(arr, index * 2 + 1); node.right = array2binary(arr, index * 2 + 2); return node; }; 这个代码只会在某些情况里正常,并不会适应 leetcode 里所有的二叉树的情况。如在513. 找树左下角的值中的第 2 个示例:输入: [1,2,3,4,null,5,6,null,null,7] 输出: 7 实际的树结构是:若使用最上面的迭代循环方式,是没有问题的,构建出来的树与例题中一样。但若使用这段递归的代码,就会出现问题,发现节点7没了。这是因为:节点 2 的右子节点为 null 时,后续数组不会再用 null 为该空节点(2 右) 来填充他的子节点。使用上面队列结构循环时,我们会跳过(2 右)这个节点,接着处理节点 5。但在递归的方式中,我们通过index * 2 + 1和index * 2 + 2来计算 arr[index]的左右节点,会把节点 7 算到(2 右)空节点的子节点上。从这里开始,后续的节点都会错位。后来又想着怎么给这个递归程序补救一下,不过没找到实现的方式。
-
实现一个带有动效的 React 弹窗组件 我们在写一些 UI 组件时,若不考虑动效,就很容易实现,主要就是有无的切换(类似于 Vue 中的 v-if 属性)或者可见性的切换(类似于 Vue 中的 v-show 属性)。 1. 没有动效的弹窗 # 在 React 中,可以这样来实现:interface ModalProps { open: boolean; onClose?: () => void; children?: any; } const Modal = ({open. onClose, children}: ModalProps) => { if (!open) { return null; } return createPortal( {children} x , document.body); }; 使用方式:const App = () => { const [open, setOpen] = useState(false); return ( setOpen(true)}>show modal setOpen(false)}> modal content ); }; 我们在这里就是使用open属性来控制展示还是不展示,但完全没有渐变的效果。若我们想实现 fade, zoom 等动画效果,还需要对此进行改造。 2. 自己动手实现有动效的弹窗 # 很多同学在自己实现动效时,经常是展示的时候有动效,关闭的时候没有动效。都是动效的时机没有控制好。这里我们先自己来实现一下动效的流转。刚开始我实现的时候,动效只有开始状态和结束状态,需要很多的变量和逻辑来控制这个动效。后来我参考了react-transition-group组件的实现,他是将动效拆分成了几个部分,每个部分分别进行控制。 展开动效的顺序:enter -> enter-active -> enter-done; 关闭动效的顺序:exit -> exit-active -> exit-done; 动效过程在enter-active和exit-active的过程中。我们再通过一个变量 active 来控制是关闭动效是否已执行关闭,参数 open 只控制是执行展开动效还是关闭动效。当 open 和 active 都为 false 时,才销毁弹窗。const Modal = ({ open, children, onClose }) => { const [active, setActive] = useState(false); // 弹窗的存在周期 if (!open && !active) { return null; } return ReactDOM.createPortal( {children} x , document.body, ); }; 这里我们接着添加动效过程的变化:const [aniClassName, setAniClassName] = useState(''); // 动效的class // transition执行完毕的监听函数 const onTransitionEnd = () => { // 当open为rue时,则结束状态为'enter-done' // 当open未false时,则结束状态为'exit-done' setAniClassName(open ? 'enter-done' : 'exit-done'); // 若open为false,则动画结束时,弹窗的生命周期结束 if (!open) { setActive(false); } }; useEffect(() => { if (open) { setActive(true); setAniClassName('enter'); // setTimeout用来切换class,让transition动起来 setTimeout(() => { setAniClassName('enter-active'); }); } else { setAniClassName('exit'); setTimeout(() => { setAniClassName('exit-active'); }); } }, [open]); Modal 组件完整的代码如下:const Modal = ({ open, children, onClose }) => { const [active, setActive] = useState(false); // 弹窗的存在周期 const [aniClassName, setAniClassName] = useState(''); // 动效的class const onTransitionEnd = () => { setAniClassName(open ? 'enter-done' : 'exit-done'); if (!open) { setActive(false); } }; useEffect(() => { if (open) { setActive(true); setAniClassName('enter'); setTimeout(() => { setAniClassName('enter-active'); }); } else { setAniClassName('exit'); setTimeout(() => { setAniClassName('exit-active'); }); } }, [open]); if (!open && !active) { return null; } return ReactDOM.createPortal( {children} x , document.body, ); }; 动效的流转过程已经实现了,样式也要一起写上。比如我们要实现渐隐渐现的 fade 效果:.enter { opacity: 0; } .enter-active { transition: opacity 200ms ease-in-out; opacity: 1; } .enter-done { opacity: 1; } .exit { opacity: 1; } .exit-active { opacity: 0; transition: opacity 200ms ease-in-out; } .exit-done { opacity: 0; } 如果是要实现放大缩小的 zoom 效果,修改这几个 class 就行。一个带有动效的弹窗就已经实现了。使用方式:const App = () => { const [open, setOpen] = useState(false); return ( setOpen(true)}>show modal setOpen(false)}> modal content ); }; 点击链接自己实现动效的 React 弹窗 demo查看效果。类似地,还有 Toast 之类的,也可以这样实现。 3. react-transition-group # 我们在实现动效的思路上借鉴了 react-transition-group 中的CSSTransition组件。CSSTransition已经帮我封装好了动效展开和关闭的过程,我们在实现弹窗时,可以直接使用该组件。这里有一个重要的属性:unmountOnExit,表示在动效结束后,卸载该组件。const Modal = ({ open, onClose }) => { // http://reactcommunity.org/react-transition-group/css-transition/ // in属性为true/false,true为展开动效,false为关闭动效 return createPortal( {children} x , document.body, ); }; 在使用 CSSTransition 组件后,Modal 的动效就方便多了。 4. 总结 # 至此已把待动效的 React Modal 组件实现出来了。虽然 React 中没有类似 Vue 官方定义的标签,不过我们可以自己或者借助第三方组件来实现。
-
如何使用 jest 和 lint-staged 只检测发生改动的文件 我们现在在推进 EPC 的过程中,单元测试是必备的技能,在本地的 Git commit 之前进行单测非常有必要,总不能把所有的单测的压力都放在流水线上。毕竟在流水线运行单测的成本还是挺高的,从 push 上去触发流水线,到感知单测的结果,至少需要好几分钟的时间。因此我们有必要在 git commit 进行一些单测的检测。不过若我们每次在 commit 之前都完整地运行所有的单测用例,一个是没必要,再一个是耗时很长。那应该怎么只运行有变动的文件的单测用例呢? 1. 使用 husky 和 lint-staged # 我们接下来要使用 husky 和 lint-staged 组件,来实现在 commit 之前检测只发生变动的文件。 husky可以让我们很方便地设置 pre-commit 的钩子; lint-staged组件能够在 Git commit 提交之前,获取上次 commit 到现在所有发生变动的文件。我们可以利用这个特性来运行 jest; 1.1 配置 husky 和 lint-staged # 首先我们来安装和配置这两个组件。$npm i husky lint-staged --save-dev $npm set-script prepare "husky install" $npm run prepare $npx husky add .husky/pre-commit "npx lint-staged" 运行完上述 4 个命令后,然后在package.json中配置 lint-staged:{ "scripts": { "test:staged": "jest --bail --findRelatedTests" }, "lint-staged": { "src/**/*.{js,jsx,ts,tsx}": ["npm run test:staged"] } } 在 lint-staged 中支持node-glob通配符的配置,同时也支持配置多个,若发生变动的文件路径满足配置,则触发后面的命令。上面通配符的意思是:src 目录中任意路径的任意以.js 或.jsx 或.ts 或.tsx 结尾的文件。 1.2 配置 jest # 我们在上面的 test:staged 命令配置上了 jest。 bail: 只要遇到运行失败的单测用例即退出; findRelatedTests: 检测指定的文件路径; 其他更多的参数,可以直接查阅官方文档Jest CLI Options。很多公共的数据,我们可以直接在jest.config.js中进行配置:module.exports = { roots: ['/src'], // 查找src目录中的文件 collectCoverage: true, // 统计覆盖率 coverageDirectory: 'coverage', // 覆盖率结果输出的文件夹 coverageThreshold: { // 所有文件总的覆盖率要求 global: { branches: 60, functions: 60, lines: 60, statements: 60, }, // 匹配到的单个文件的覆盖率要求 // 这里也支持通配符的配置 './src/**/*.{ts,tsx}': { branches: 40, functions: 40, lines: 40, statements: 40, }, }, // 匹配单测用例的文件 testMatch: ['/src/**/__tests__/**/*.{js,jsx,ts,tsx}', '/src/**/*.{spec,test}.{js,jsx,ts,tsx}'], // 当前环境是jsdom还是node testEnvironment: 'jsdom', // 设置别名,若不设置,运行单测时会不认识@符号 moduleNameMapper: { '^@/(.*)$': '/src/$1', }, }; 上面两个配置完成后,当本次 commit 发生变动的文件满足要求,至少有 1 个文件满足时,则就会执行npm run test:staged。我们先运行下所有的测试用例:可以看到,我们实际上有 2 个源文件,3 个测试文件。不过 add 相关的已经在上次 commit 提交过了,本次提交时,只有 uitils 和 utils.test 有变动。$git add . $git ci -m 'test(utils): only test utils changed file' 从给出的测试报告能看出来,当前只检测了发生变动的 utils 文件: 2. 覆盖率的要求 # 我们在上面通过 jest.config.js 中的coverageThreshold属性,设置了全局覆盖率和单个文件的覆盖率。我们再在代码新增几个文件,但不配置对应的测试文件。然后运行时发现,如果没有对应的测试文件,就不会检查该文件的覆盖率。我这里特意把概率设置 100%,然后 math.js 没有对应的测试文件:从运行的测试结果来,这里只检测了有测试文件的 utils.js,并没有检测到 math.js。这里我们就要新增一个属性了collectCoverageFrom:{ collectCoverageFrom: ["src/**/*.{js,jsx,ts,tsx}"], } 这时,我们再运行单测时,就能把所有符合要求的文件,都纳入到覆盖率的考核里了。 3. collectCoverageFrom 的坑 # 我们在使用 commit 提交时,会触发lint-staged,按我们在第 1 节说的,应该只运行发生变动的实例,覆盖率也只输出当前运行的实例。但实际上并不是如此,若配置了collectCoverageFrom,无论是怎样运行单测,他都会输出所有符合要求的文件的覆盖率数据:从黄色框框中可以看到,我们本次只提交了 utils.js,按说应该只运行和计算 utils.js 的单测覆盖率即可,但实际上会把所有的覆盖率都输出出来,然后大部分数据为 0,无法满足设置的覆盖率的要求。但我们又不能不设置 collectCoverageFrom 属性,最后我的解决办法是:排除法:{ collectCoverageFrom: ['!src/**/*.d.ts', '!src/**/*{.json,.snap,.less,.scss}'], } 这样我们在 commit 提交时,就能满足只从被检测的文件中提取覆盖率。 4. 总结 # 工欲兴其事,必先利其器。当我们提前把配置搭建完成后,就可以进行开发啦。