搜索到
792
篇与
的结果
-
 如何文明提交代码 程序员最烦的几件事:写测试,变量命名,还有填代码提交信息(commit message)。翻几个开源项目遍马上可以回味那作文凑字数的青春时光。其实 commit message 的作用远不止如此,经过简单的配置便可无痛成为代码提交的文明公民。Commit Message 的作用最起码的一点,项目的提交历史是其他人(包括未来的自己)了解项目的一个重要途径。好的提交历史可以方便其他人参与进来,也可以方便自己快速定位问题。此外,提交信息还可以用来触发 CI 构建,自动生成 CHANGELOG ,版本自动语义化提升…… 只需要一点点配置就可以干这么多,真是懒人必备。选择风格跟 Code Style 一样,Commit Message 也有各种风格。如果没什么特殊癖好推荐用基于 Angular , 后独立开来的 Conventional Commits 风格。 它也基本是各个工具的默认配置,所以搭配起来不需要折腾。才不要又记什么规则虽然规则不多,但不一定能随时记住,特别是对新人,必须要有友好的方式提交。commitizen 是一个很好的选择,通过命令行回答几个问题即可填完信息,减轻了记忆负担。 它是一个通用的工具,通过插件方式支持各种风格。我们选择 Conventional 需要安装 cz-conventional-changelog 。npm install --save-dev commitizen cz-conventional-changelog然后配置 package.json 就可以通过 npm run commit 提交。{ "scripts": { "commit": "git-cz" } }另外 VSCode 用户也可以用 vscode-commitizen , 通过 ctrl+shift+p 或 command+shift+p 提交。Lint 一 Lint 万无一失没错,Commit Message 也有 Linter ,可对 Commit Message 进行检验,杜绝打字手残和浑水摸鱼。这里用 commitlint 配合 husky 实现自动检测。commitlint 也是通用的工具,需要同时安装风格配置。 husky 可以方便使用 git hooks ,在 commit 时触发 commitlint 。npm install --save-dev @commitlint/cli @commitlint/config-conventional husky项目根新建 commitlint.config.jsmodule.exports = { extends: ['@commitlint/config-conventional'] }配置 package.json{ "husky": { "hooks": { "commit-msg": "commitlint -E HUSKY_GIT_PARAMS" } }, }自动更新最后安装 standard-version 实现自动生成 CHANGELOG 和版本自动语义化提升。npm install --save-dev standard-version配置 package.json{ "scripts": { "release": "standard-version" } }第一次发布时可以用以下命令重置npm run release -- --first-release以后直接 npm run release 即可。也可以手动指定版本:# npm run script npm run release -- --release-as minor # Or npm run release -- --release-as 1.1.0小红花贴起来在 README 中加入小徽章可方便其他人了解风格。[](http://commitizen.github.io/cz-cli/) [](https://conventionalcommits.org)完整配置安装npm install --save-dev commitizen cz-conventional-changelog @commitlint/cli @commitlint/config-conventional husky standard-version配置 package.json{ "scripts": { "commit": "git-cz", "release": "standard-version" }, "husky": { "hooks": { "commit-msg": "commitlint -E HUSKY_GIT_PARAMS" } }, }项目根新建 commitlint.config.jsmodule.exports = { extends: ['@commitlint/config-conventional'] }【完】
如何文明提交代码 程序员最烦的几件事:写测试,变量命名,还有填代码提交信息(commit message)。翻几个开源项目遍马上可以回味那作文凑字数的青春时光。其实 commit message 的作用远不止如此,经过简单的配置便可无痛成为代码提交的文明公民。Commit Message 的作用最起码的一点,项目的提交历史是其他人(包括未来的自己)了解项目的一个重要途径。好的提交历史可以方便其他人参与进来,也可以方便自己快速定位问题。此外,提交信息还可以用来触发 CI 构建,自动生成 CHANGELOG ,版本自动语义化提升…… 只需要一点点配置就可以干这么多,真是懒人必备。选择风格跟 Code Style 一样,Commit Message 也有各种风格。如果没什么特殊癖好推荐用基于 Angular , 后独立开来的 Conventional Commits 风格。 它也基本是各个工具的默认配置,所以搭配起来不需要折腾。才不要又记什么规则虽然规则不多,但不一定能随时记住,特别是对新人,必须要有友好的方式提交。commitizen 是一个很好的选择,通过命令行回答几个问题即可填完信息,减轻了记忆负担。 它是一个通用的工具,通过插件方式支持各种风格。我们选择 Conventional 需要安装 cz-conventional-changelog 。npm install --save-dev commitizen cz-conventional-changelog然后配置 package.json 就可以通过 npm run commit 提交。{ "scripts": { "commit": "git-cz" } }另外 VSCode 用户也可以用 vscode-commitizen , 通过 ctrl+shift+p 或 command+shift+p 提交。Lint 一 Lint 万无一失没错,Commit Message 也有 Linter ,可对 Commit Message 进行检验,杜绝打字手残和浑水摸鱼。这里用 commitlint 配合 husky 实现自动检测。commitlint 也是通用的工具,需要同时安装风格配置。 husky 可以方便使用 git hooks ,在 commit 时触发 commitlint 。npm install --save-dev @commitlint/cli @commitlint/config-conventional husky项目根新建 commitlint.config.jsmodule.exports = { extends: ['@commitlint/config-conventional'] }配置 package.json{ "husky": { "hooks": { "commit-msg": "commitlint -E HUSKY_GIT_PARAMS" } }, }自动更新最后安装 standard-version 实现自动生成 CHANGELOG 和版本自动语义化提升。npm install --save-dev standard-version配置 package.json{ "scripts": { "release": "standard-version" } }第一次发布时可以用以下命令重置npm run release -- --first-release以后直接 npm run release 即可。也可以手动指定版本:# npm run script npm run release -- --release-as minor # Or npm run release -- --release-as 1.1.0小红花贴起来在 README 中加入小徽章可方便其他人了解风格。[](http://commitizen.github.io/cz-cli/) [](https://conventionalcommits.org)完整配置安装npm install --save-dev commitizen cz-conventional-changelog @commitlint/cli @commitlint/config-conventional husky standard-version配置 package.json{ "scripts": { "commit": "git-cz", "release": "standard-version" }, "husky": { "hooks": { "commit-msg": "commitlint -E HUSKY_GIT_PARAMS" } }, }项目根新建 commitlint.config.jsmodule.exports = { extends: ['@commitlint/config-conventional'] }【完】 -
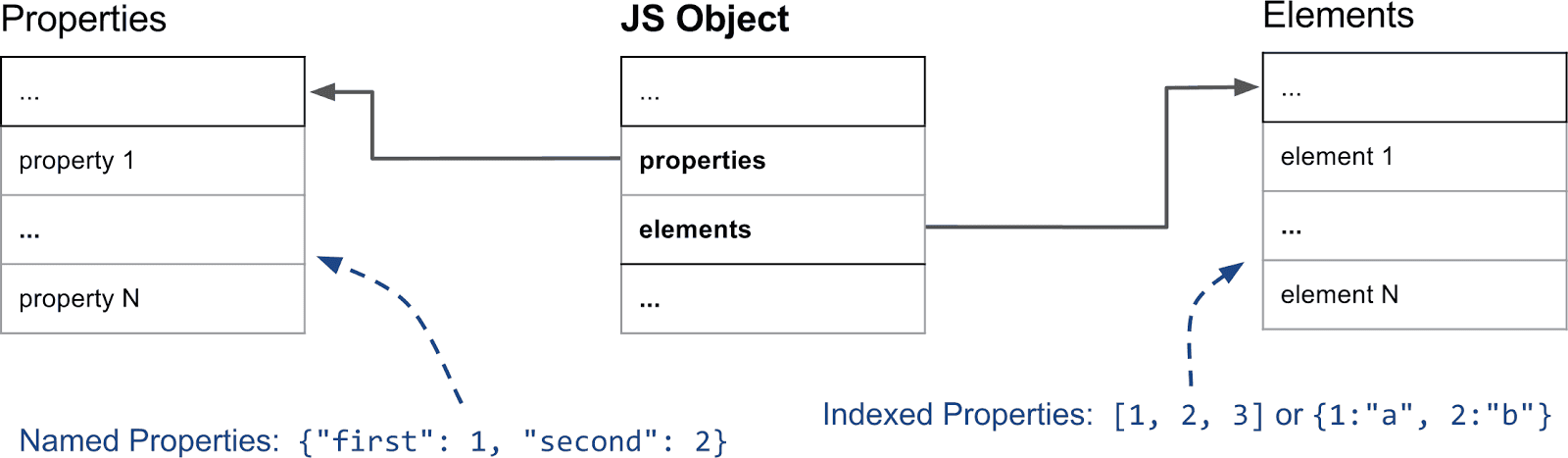
V8 中的快属性 译自:Fast properties in V8(2017-08-30)本文我们将解释 V8 内部如何处理 JavaScript 属性(properties)。从 JavaScript 的角度来看属性只有少数的区别。JavaScript 对象通常跟字典(dictionaris)差不多,以字符串为键,任意对象为值。尽管规范确实对迭代过程中的整数索引属性与其他属性作了区分,但除此以外,不同属性表现基本是一致的,不管是不是整数索引。然而,在底层 V8 的确依赖了一些不同的属性表示方式,这是出于性能和内存考虑的。本文我们将解释 V8 如何在提供快属性访问的同时支持动态添加属性。理解属性如何工作对解释 V8 内联缓存之类的优化原理是必不可少的。本文解释了整数索引与命名属性的不同处理方式。随后我们展示了 V8 如何在添加命名属性同时维护隐藏类(HiddenClasses),以提供快速的方式识别一个对象的形状(shape)。接着我们继续深入了解命名属性是如何根据使用方式来进行优化,以支持快速访问和快速修改。最后部分我们详细介绍了 V8 如何处理整数索引属性或数组索引。命名属性与元素首先我们来分析一个简单的对象 {a: "foo", b: "bar"}。这个对象有两个命名属性,"a" 和 "b",没有任何整数索引作属性名。数组索引属性(array-indexed properties),常叫元素(elements),在数组中非常重要。比如数组 ["foo", "bar"] 有两个数组索引属性:0 与值 "foo" ,和 1 与值 "bar"。 这是 V8 如何处理属性的第一个主要区别。下图展示了一个基本 JavaScript 对象在内存中是什么样的。 元素和属性被保存在两个独立的数据结构中。两者的使用方式通常不一样,故这能让添加和访问属性或元素更加高效。元素主要被用在各种 Array.prototype 方法中,如 pop 或者 slice。考虑到这些函数都是连续地访问属性,V8 内部还将它们表示为简单的数组,大多数情况下都是如此。本文后面还会解释到有时我们如何切换到基于稀疏字典的表示来节省内存。命名属性也是通过类似的方式存在另外的数组中。但是,跟元素不同,我们不能简单地通过键来推断出它们在属性数组中的位置,我们需要一些额外的元数据。在 V8 中每个 JavaScript 对象都关联了一个隐藏类(HiddenClasses)。隐藏类保存了对象的形状信息,以及从属性名称到属性索引的映射。复杂的使用情况下我们有时会用字典来存属性而不是简单的数组。我们会在专门的部分再作详细地解释。本节要点: 数组索引属性被保存在独立的元素存储中。 命名属性被保存在属性存储中。 元素和属性可以是数组或者字典。 每个 JavaScript 对象都有相应的隐藏类来记录该对象的形状信息。 隐藏类和描述符数组在解释了元素和命名属性的一般区别之后,我们需要看看隐藏类在 V8 中是如何工作的。隐藏类保存了与对象相关的元信息,包括对象上的属性数和对象原型的引用。隐藏类在概念上与典型面向对象编程语言中的类相似。但是,在基于原型的语言(如 JavaScript)中,通常不可能预先知道类。因此,在这种情况下,V8 的隐藏类是动态创建的,并随着对象的变化而动态更新。隐藏类充当了对象形状的标识符,因此是 V8 优化编译器和内联缓存非常重要的组成部分。比如优化编译器可以直接内联属性访问,如果它可以通过隐藏类来确保对象结构是兼容的。我们来看看隐藏类的重要部分。 在 V8 中,JavaScript 对象的第一个字段指向隐藏类(事实上,任何在 V8 堆上且由垃圾收集器管理的对象都是这种情况)。在属性中,最重要的信息是第三位字段,它保存了属性数以及描述符数组的指针。描述符数组包含了有关命名属性的信息,例如名称本身以及值保存的位置。注意我们不会在此处跟踪整数索引属性,故描述符数组中没有相关条目。对于隐藏类的基本判断标准是,具有相同结构的对象(如属性命名相同且顺序相同)共享相同的隐藏类。为了实现这一点,对象在添加属性后我们将使用不同的隐藏类。在下面的示例中,我们从一个空对象开始并添加三个命名属性。 每次添加新属性时,对象的隐藏类都会被更改。在引擎的底层,V8 创建了一个将隐藏类链接在一起的转换树(transiton tree)。当你向一个空对象添加属性(如“a”)时,V8 会知道要采用哪个隐藏类。如果以相同的顺序添加相同的属性,此转换树会确保最后得到的是相同的最终隐藏类。以下示例显示,即使我们在其间添加了简单的索引属性,我们还是得到了相同的转换树。 然而,如果我们创建一个添加了不同属性的新对象,如属性 "d",则 V8 会为新的隐藏类创建一个单独的分支。 本节要点: 具有相同结构的对象(相同顺序相同属性)具有相同的隐藏类。 默认情况下,每添加新的命名属性都会导致一个新的隐藏类被创建。 添加数组索引属性不会创建新的隐藏类。 三种不同的命名属性在概述了 V8 如何使用隐藏类跟踪对象的形状之后,让我们深入了解这些属性的实际存储方式。正如上面介绍中所解释的,属性有两种基本类型:命名和索引。以下部分先介绍命名属性。一个简单的对象如 {a:1,b:2} 在 V8 中可以有多种内部表示。虽然 JavaScript 对象在外部看来或多或少类似于简单的字典,但 V8 试图避免使用字典,因为它们妨碍了某些优化,如内联缓存,我们会在其它文章中再作解释。对象与普通属性: V8 支持所谓的对象内属性(in-object properties),指这些属性直接存储在对象本身上。它们在 V8 可用的属性中是最快的,因为它们不需要间接层就可以访问。对象内属性的数量由对象的初始大小预先确定。如果添加的属性超出了对象分配的空间,则它们将被保存在属性存储中。属性存储多了一层间接层,但可以自由地扩容。 快属性与慢属性: 下一个重要区别是快属性和慢属性。通常,我们将保存在线性属性存储中的属性定义为“快”。只需通过属性存储中的索引即可访问快属性。要从属性名称获取属性存储中的实际位置,我们必须查看隐藏类上的描述符数组,如前面所述。 但是,如果从对象中添加和删除大量属性,则可能会产生大量时间和内存开销来维护描述符数组和隐藏类。因此 V8 还支持所谓的慢属性。带慢属性的对象内部会有独立的词典作为属性存储。所有的属性元信息不再保存在隐藏类的描述符数组中,而是直接保存在属性字典中。因此无需更新隐藏类即可添加和删除属性。由于内联缓存不适用于字典属性,故后者通常比快属性慢。本节要点: 有三种不同的命名属性类型:对象内属性、快属性和慢属性(字典)。 对象属性直接保存在对象本身上,并提供最快的访问。 快属性保存在属性存储中,所有元信息都存储在隐藏类的描述符数组中。 慢属性保存在内部独立的属性字典中,不再通过隐藏类共享元信息。 慢属性允许高效的属性删除和添加,但访问速度比其它两种类型慢。 元素与数组索引属性到目前为止,我们一直在讨论命名属性,而忽略了常用于数组的整数索引属性。处理整数索引属性并不比命名属性简单。尽管所有索引属性都是在元素存储中单独保存,但不同类型的元素也有 20 种!挤满的还是带空隙的元素: V8 做的第一个主要区分看是元素后备存储(elements backing store)是挤满的(packed)还是带空隙的(holey)。当索引元素被删除,又或者如,没有被定义,后备存储中就会出现空隙。如一个简单的例子 [1,,3],其中的第二个条目就是一个空隙。以下示例说明了此问题:const o = ['a', 'b', 'c']; console.log(o[1]); // 打印 'b'. delete o[1]; // 在元素存储中引入空隙 console.log(o[1]); // 打印 'undefined',属性 1 不存在 o.__proto__ = {1: 'B'}; // 在原型中定义属性 1 console.log(o[0]); // 打印 'a'. console.log(o[1]); // 打印 'B'. console.log(o[2]); // 打印 'c'. console.log(o[3]); // 打印 undefined 简而言之,如果接收方(receiver)上没有发现属性,我们就必须沿着原型链继续查找。鉴于元素是内部独立的(比如,我们不会在隐藏类上保存有关当前索引属性的信息),我们需要一个特殊值,称为 _hole,来标记不存在的属性。这对于数组函数的性能是至关重要的。如果我们知道没有空隙,即元素存储是挤满的,我们就可以直接在当前域执行操作而无需沿着原型链做昂贵的查找。快元素还是字典元素: V8 对元素做的第二个主要区分是看它们是在快速模式还是字典模式。快元素是简单的虚拟机内部数组,其中的属性索引映射到元素存储中的索引。然而,这种简单的表示对于非常大的稀疏/带空隙的数组而言是相当浪费的,其中只有很少的条目被占用。在这种情况下,我们使用基于字典的表示来节省内存,但代价是访问速度稍慢:const sparseArray = []; sparseArray[9999] = 'foo'; // 创建了一个基于字典元素的数组在这个例子中,开辟一个包含一万条目的完整数组会相当浪费。相反,V8 会创建一个字典来存储键-值-描述符三元组。在这个例子中,键是 '9999',值是 'foo',默认描述符被使用。由于我们没有办法在隐藏类上保存描述符的详细信息,故只要你使用了自定义描述符去定义索引属性,V8 就会采用慢元素:const array = []; Object.defineProperty(array, 0, {value: 'fixed' configurable: false}); console.log(array[0]); // 打印 'fixed'。 array[0] = 'other value'; // 不能重写索引 0。 console.log(array[0]); // 依然打印 'fixed'。在这个例子中,我们在数组上添加了一个不可配置的属性。该信息保存在慢元素字典三元组的描述符部分中。需要注意的是,在带有慢元素的对象上数组函数的执行速度会慢很多。小整数和双浮点元素: 对于快元素,V8 中还有另一个重要的区分。比如一个常见的例子,只在一个数组中放整数,那么垃圾回收器就不必查看数组,因为整数被直接编码为所谓的小整数(Smis)。另一个特例是只包含双浮点数(double)的数组。与小整数不同,浮点数通常表示为占据多个字(word)的完整对象。然而,在 V8 中,纯双浮点数的数组会使用原生双精度浮点数来保存,以减少内存和性能开销。以下例子列出了小整数和双浮点元素的四个示例:const a1 = [1, 2, 3]; // 挤满小整数 const a2 = [1, , 3]; // 带空隙小整数,a2[1] 从原型中读取 const b1 = [1.1, 2, 3]; // 挤满双浮点 const b2 = [1.1, , 3]; // 带空隙双浮点,b2[1] 从原型中读取特殊元素: 到目前为止,我们已经涵盖了 20 种不同元素中的 7 种。为简单起见,我们排除了 9 种 TypedArrays 相关的元素类型,2 种 String 包装器相关的,还有 2 种参数对象相关的特殊类型。元素访问器: 正如你所想的,我们并不太热衷于在 C++ 中给元素种类一个个对应地写 20 多遍数组函数。这里就需要一些 C++ 魔术。我们不是一遍又一遍地实现数组函数,而是构建了元素访问器 ElementsAccessor,这样我们大多情况下只需要实现简单的函数来从后备存储中访问元素。ElementsAccessor 依赖于 CRTP 来创建每个数组函数的专用版本。因此,如果在数组上调用类似 slice 的方法,V8 内部会调用 C++ 编写的内置函数,并通过 ElementsAccessor 调度到函数的专用版本: 本节要点: 索引属性和元素有快速和字典模式。 快属性可以是挤满的(packed),也可以包含空隙(holes)表示索引属性被删除。 不同类型的元素根据其内容专门优化,以加速数组函数并减少垃圾回收器开销。 了解属性如何工作是 V8 中许多优化的关键。对于 JavaScript 开发者来说,许多这样的内部决策都不是直接可见的,但它们解释了为什么某些代码模式比其它的更快。更改属性或元素类型通常会导致 V8 创建一个不同的隐藏类,这可能导致类型污染阻止 V8 生成最优代码。请继续关注有关 V8 虚拟机内部工作原理的更多文章。
-
搭建 Gatsby 博客一:为什么选 Gatsby 为什么选 Gatsby我的博客最初是用 Github Pages 默认的 Jekyll 框架,其使用的 Liquid 模板引擎在使用上有诸多不便。后来基于 Node.js 的 Hexo 横空出世,我便重构了博客对其深入整合,还为其写了一个 emoji 插件。在编写过程中发现其 API 设计比较不成熟,调试体验也不是很好,阅读其它插件代码时发现很多都需要用到未公开接口。同时资源管理需要借助其它 Task runner,如当时比较流行的 Grunt 和 Gulp 。这样下来直接依赖了大量包,冲突不可避免的产生。在一次换系统之后,项目终于构建不了了,包冲突处理起来非常头疼,也影响到了写博文的兴致。拖延了一段时间后,终于开始考虑更换框架。这时 React Angular Vue 生态已比较成熟,所以就没必要考虑其它的模板引擎。首先注意到的是新星 VuePress 。然而考察过后发现其正在 v1 到 v2 的更替期,v1 功能比较简陋,v2 还在 alpha 期不稳定。且 VuePress 目前还是针对静态文档优化比较多,作为博客依然比较简陋。这时 @unicar 正好推荐了基于 React 的 Gatsby。发现其生态很强大,再搭配 React 庞大的生态,确实非常吸引人。而且在了解过程中还发现了 Netlify CMS 这个内容管理平台,如此一来,文章数据完全可以存在 Github 中,同时可以便捷地编辑文章。Gatsby 项目结构建议使用 Starter 修改着理解 Gatsby,我用的是 Gatsby + Netlify CMS Starter。完整的 Gatsby 项目结构可以看文档,这里针对搭建博客用到的功能说明一下。 /src/pages 目录下的组件会被生成同名页面。 /src/templates 目录下放渲染数据的模板组件,如渲染 Markdown 文章,在其它博客系统中一般叫 layout。 /src/components 一般放其它共用的组件。 /static 放其它静态资源,会跳过 Webpack 直接复制过去。 接下来是两个比较常用的配置文件,需要修改时参考 Starter 改即可。 /gatsby-config.js 基本用来配置两个东西: siteMetadata 放一些全局信息,这些信息在每个页面都可以通过 GraphQL 获取到。 plugins 配置插件,这个按用到时按该插件文档说明弄即可。 /gatsby-node.js 可以调用 Gatsby node APIs 干一些自动化的东西。一般有两个常用场景: 添加额外的配置,比如为 Markdown 文章生成自定义路径。 生成 /src/pages 以外的页面文件,如为每个 Markdown 文章生成页面文件。 此外还有两个不那么常用的配置文件。 /gatsby-browser.js 可以调用 Gatsby 浏览器 APIs,一般插件才会用到,如滚动到特定位置。 /gatsby-ssr.js 服务器渲染的配置,一般也是插件才用到。 这就是搭建 Gatsby 博客的基本结构了,可以看到非常简单,且因为其丰富的生态,其它底层接口基本不需要用到。但接下来还是会有一些小坑,第一个便是 GraphQL,我会在下一篇文章中分析。
-
搭建 Gatsby 博客二:使用 GraphQL 管理资源 为什么用 GraphQL上一篇介绍了选择 Gatsby 的原因,其中提到了 Gatsby 使用 GraphQL 。大家可能会有疑惑,不是建静态博客么,怎么会有 GraphQL?难道还要部署服务器?其实这里 GraphQL 并不是作为服务器端部署,而是作为 Gatsby 在本地管理资源的一种方式。通过 GraphQL 统一管理实际上非常方便,因为作为一个数据库查询语言,它有非常完备的查询语句,与 JSON 相似的描述结构,再结合 Relay 的 Connections 方式处理集合,管理资源不再需要自行引入其它项目,大大减轻了维护难度。带魔法的 GraphQL这里也是 Gatsby 的第一个坑。在 Gatsby 中,根据 js 文件的位置不同,使用 GraphQL 有两种形式,且 Gatsby 对其做了魔法,在 src/pages 下的页面可以直接 export GraphQL 查询,在其它页面需要用 StaticQuery 组件或者 useStaticQuery hook。这里面查询语句虽然写的是字符串,但其实这些查询语句不会出现在最终的代码中,Gatsby 会先对其抽取。个人其实不太喜欢魔法,因为会增加初学者的理解难度。但不得不承认魔法确实很方便,就是用了魔法的项目应该在文档最显眼的地方说明一遍。快速上手 GraphQLGraphQL 结构跟最终数据很相似,基本语法也非常简单,看看官方文档即可。一个快速上手的方式是访问项目开发时(默认 http://localhost:8000)的 /___graphql 页面,通过 GraphiQL 编辑器右侧可以浏览所有能够查询的资源。另一个需要理解的是 Relay 的 Connections 概念,你会发现 Gatsby 里所有的数据集合都是以这种方式查询。推荐阅读 Apollo 团队分享的文章。对 Connections 细致的理解往往是实现分页等底层需求时才需要,而这些均有插件完成。一般使用时只需要知道集合里每个项目的数据在 edges.node 中,同时通过 GraphiQL 浏览其它可以使用的数据。如对于 Markdown 文章,相应插件提供了字数统计以及阅读时长等数据,均可通过 GraphQL 直接获取。Debug GraphQLGatsby 魔法带来的另外一个坑是 GraphQL 报错信息不全,可能会默默被吞掉,也可能无法定位到最终文件。我在修改 starter 时踩到一个坑是复制组件时忘了修改 static query 查询语句的名称,导致重名报错。避免错误最好方式是在 GraphiQL 编辑器中写好运行无误再复制到组件中。Remark 插件坑Gatsby 中处理 markdown 最常用也是默认的插件是 gatsby-transformer-remark。这个插件对 markdown 文件解析后会生成 MarkdownRemark GraphQL 节点,其中 front matters 数据也会被解析出来。同时 MarkdownRemark 的集合对应为 allMarkdownRemark connections。对于 connections 节点我们一般可以用 sort 和 filter 来筛选处理数据(可在 GraphiQL 编辑器中浏览),这里有一个坑便是如果要处理 front matters 数据,它们必须存在所有查询的 markdown 文件上并且具有相同的类型,插件才会生成相应的 fields,否则可能会抛出异常或者更糟糕的,默默失败了。避免方式同上,先在 GraphiQL 编辑器中运行一遍,看看筛选的结果是否正确。另外一种处理方式是在 /gatsby-node.js 中通过 onCreateNode 钩子,在生成 markdown 相关节点时手工处理,确保节点存在。这在实现草稿和上下篇的时候会用到,具体例子我会在后续文章中再写。
-
搭建 Gatsby 博客三:使用 Netlify CMS 管理文章 为什么选择 Netlify CMS搭建 Gatsby 博客其实不需要 CMS 都是可以的,编写 Markdown 然后 build 即可。但这么做还是略嫌不便,通过 CMS 一般可以在一个可视化的在线环境中编辑文章,然后一键即可发布。Gatsby 主流的两个 CMS 是 Contentful 和 Netlify CMS。对于 Contentful 来说,文章是放在 Contentful 的服务器上的,管理也是通过 Contentful 提供的工具。当然其质量还是不错的,喜欢的可以参照官方的教程搭建。Netlify CMS 是跟项目一起发布的,默认是在 /admin 页面下。文章也是存在源项目中,就是原来默认的 Markdown 文件。Netlify CMS 借助 Oauth 把写好的 Markdown 文件推送到项目源码的仓库上,再配合 Netlify 检测仓库变动自动构建发布。当然后者也不是必须的,可以换其它方式自动构建。Netlify CMS 的优点是开源免费,文章跟项目源码在一起,界面可以高度自定义,甚至可以自行扩充 React 组件,基本满足简单的博客编写需求。配置 Netlify CMS如果用官方的 starter 配置将会非常简单。此 starter 默认使用 Github 作为仓库,Netlify 作为自动构建服务器。配置 Widgets默认的 /static/admin/config.yml 已经配置好了大部分,如果对文章 Markdown 添加了自定义的 front matters 则需要再做些细调。Widgets 代表了在 CMS 中可输入的模块,官方为常见的类型都提供了默认的 widgets ,没有满足的也可以自定义。如我的博客中每篇文章都有一个 quote 域放些引用文字,那么在配置中添加上fields: - label: "Quote" name: "quote" widget: "object" fields: - {label: "Content", name: "content", widget: "text", default: "", required: false} - {label: "Author", name: "author", widget: "string", default: "", required: false} - {label: "Source", name: "source", widget: "string", default: "", required: false}如此即可在 CMS 中填写相关信息。配置预览CMS 中提供了文章预览界面,如果需要自定义只需修改 /src/cms/ 下相应的文件即可,就是简单的 React 组件。以上便是 Netlify CMS 最常用的配置,只需简单的修改博客现在就能跑起来了。接下来的文章我们会通过实现草稿模式和上下篇文章来深入理解 Gatsby 的机制。